一. ES安装
1.1 本地安装
- 下载对应系统的安装包:下载地址
- 前台启动
cd elasticsearch-<version>
./bin/elasticsearch
- 作为守护进程后台启动
cd elasticsearch-<version>
./bin/elasticsearch -d
- 测试是否启动成功
curl ‘http://localhost:9200/?pretty‘
"name" : "Meltdown", "cluster_name" : "elasticsearch", "cluster_uuid" : "ysXZW5y_TNmPh-oKLJYEvg", "version" : { "number" : "2.4.3", "build_hash" : "d38a34e7b75af4e17ead16f156feffa432b22be3", "build_timestamp" : "2016-12-07T16:28:56Z", "build_snapshot" : false, "lucene_version" : "5.5.2" }, "tagline" : "You Know, for Search" }
1.2 docker安装
- 基本命令
docker run –d –p 9200:9200 –p 9300:9300 –v /Users/lay/dockerspace/elasticsearch/master/config:/usr/share/elasticsearch/config –v /Users/lay/dockerspace/elasticsearch/master/data:/usr/share/elasticsearch/data —name=elasticsearch–test elasticsearch –Des.node.name=“TestNode”
二. 基本概念
- 索引(名词)
一个 索引 类似于传统关系数据库中的一个 数据库 ,是一个存储关系型文档的地方,是ES对逻辑数据的逻辑存储,索引的结构是为快速有效的全文检索做准备。 索引 (index) 的复数词为 indices 或 indexes 。
- 索引(动词)
索引一个文档 就是存储一个文档到一个 索引 (名词)中以便它可以被检索和查询到。这非常类似于 SQL 语句中的 INSERT 关键词,除了文档已存在时新chaj文档会替换旧文档情况之外。
- 倒排索引
倒排索引源于实际应用中需要根据属性的值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)。带有倒排索引的文件我们称为倒排索引文件,简称倒排文件(inverted file)。
- 文档
存储在ES上的主要实体叫文档
- 文档类型(废弃)
在ES中,一个索引对象可以存储很多不同用途的对象。
- 映射
存储有关字段的信息,每一个文档类型都有自己的映射。
- 面向文档
在应用程序中对象很少只是一个简单的键和值的列表。通常,它们拥有更复杂的数据结构,可能包括日期、地理信息、其他对象或者数组等。
Elasticsearch面向文档的,意味着它存储整个对象或 文档。Elasticsearch不仅存储文档,而且 索引每个文档的内容使之可以被检索。在Elasticsearch 中,你对文档进行索引、检索、排序和过滤而不是对行列数据。这是一种完全不同的思考数据的方式,也是Elasticsearch 能支持复杂全文检索的原因。
三. ES交互语法
3.1 基本结构
curl -X<VERB> ‘<PROTOCOL>://<HOST>:<PORT>/<PATH>?<QUERY_STRING>‘ -d ‘<BODY>‘
| < > | 描述 |
|---|---|
| VERB | 适当的 HTTP 方法 或 谓词 : GET、 POST、 PUT、 HEAD 或者 DELETE |
| PROTOCOL | http 或者 https(如果你在 Elasticsearch 前面有一个https 代理) |
| HOST | Elasticsearch 集群中任意节点的主机名,或者用 localhost 代表本地机器上的节点 |
| PORT | 运行 Elasticsearch HTTP 服务的端口号,默认是 9200 |
| PATH | API 的终端路径(例如 _count 将返回集群中文档数量)。Path 可能包含多个组件,例如:_cluster/stats 和 _nodes/stats/jvm |
| QUERY_STRING | 任意可选的查询字符串参数 (例如 ?pretty 将格式化地输出 JSON 返回值,使其更容易阅读) |
| BODY | 一个 JSON 格式的请求体 (如果请求需要的话) |
举例:
curl -XGET 'http://localhost:9200/_count?pretty' -d '
{
"query": {
"match_all": {}
}
}
'
3.2 常用命令
- 检测集群是否健康
curl ‘localhost:9200/_cat/health?v’
- 查看分片状态
curl –X GET ‘http://localhost:9200/_cluster/health?pretty‘
- 获取集群节点
curl ‘localhost:9200/_cat/nodes?v’
- 列出所有索引
curl ‘localhost:9200/_cat/indices?v’
- 查询索引数据
curl ‘localhost:9200/brand/_search?pretty=true‘
- 创建索引
curl -XPUT ‘localhost:9200/customer?pretty’
- 删除索引
curl –XDELETE ‘http://localhost:9200/customer‘
- 插件安装
./plugin install mobz/elasticsearch-head
- 中文分词插件
./plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v1.10.6/elasticsearch-analysis-ik-1.10.6.zip
- 后台启动安装
./elasticsearch -d
- 分析器-分析语句
curl -XGET 'localhost:9200/_analyze?pretty' -H 'Content-Type: application/json' -d'
{
"analyzer": "standard",
"text": "Text to analyze"
}
'
3.3. 查询命令
- query_string语法
curl -XGET 'localhost:9200/product/spu/_search?pretty=true' -d '{
"query" : {
"query_string" : {"query" : "brandName:本田"}
}
}'
- 分页查询
curl -XGET 'localhost:9200/product/spu/_search?pretty=true' -d '{
"from" : 1,
"size" : 1,
"query" : {
"query_string" : {"query" : "brandName:本田"}
}
}'
- 增加version值
curl -XGET 'localhost:9200/product/spu/_search?pretty=true' -d '{
"version" : true,
"from" : 1,
"size" : 1,
"query" : {
"query_string" : {"query" : "brandName:本田"}
}
}'
- 限制得分
curl -XGET 'localhost:9200/product/spu/_search?pretty=true' -d '{
"version" : true,
"min_score" : 2.4,
"query" : {
"query_string" : {"query" : "brandName:本田"}
}
}'
- 选择要返回的字段
curl -XGET 'localhost:9200/product/spu/_search?pretty=true' -d '{
"fields" : ["brandName","spuName"],
"version" : true,
"min_score" : 2.4,
"query" : {
"query_string" : {"query" : "brandName:本田"}
}
}'
- 部分字段(验证失败,可能是版本相关)
curl -XGET 'localhost:9200/product/spu/_search?pretty=true' -d '{
"partial_fields" : {
"partial1" : {
"include" : ["brand*"],
"exclude" : ["spu*"]
}
},
"query" : {
"query_string" : {"query" : "brandName:本田"}
}
}'
- 脚本字段(验证失败)
curl -XGET 'localhost:9200/product/spu/_search?pretty=true' -d '{
"script_fields" : {
"newPrice" : {
"script" : "_source.guidePrice - reducePrice",
"param" : {
"reducePrice" : 10000
}
}
},
"query" : {
"query_string" : {"query" : "brandName:本田"}
}
}'
- 用constant_score转换query为filter
curl -XGET 'localhost:9200/product/spu/_search?pretty' -H 'Content-Type: application/json' -d'
{
"query" : {
"constant_score" : {
"filter" : {
"term" : {
"spuName" : "手"
}
}
}
}
}
'
- 组合filter
curl -XGET 'localhost:9200/my_store/products/_search?pretty' -H 'Content-Type: application/json' -d'
{
"query" : {
"filtered" : {
"filter" : {
"bool" : {
"should" : [
{ "term" : {"price" : 20}},
{ "term" : {"productID" : "XHDK-A-1293-#fJ3"}}
],
"must_not" : {
"term" : {"price" : 30}
}
}
}
}
}
}
'
3.4. 分析命令
- 基本语法
curl -XGET 'localhost:9200/product/_analyze?pretty' -H 'Content-Type: application/json' -d' { "field": "spuName", "text": "手动" } '
3.5. 查询验证命令
- 基本语法
curl -XGET 'localhost:9200/my_index/my_type/_validate/query?explain&pretty' -H 'Content-Type: application/json' -d' { "query": { "bool": { "should": [ { "match": { "title": "Foxes"}}, { "match": { "english_title": "Foxes"}} ] } } } '
3.6. 批量操作
- 基本语法
bulk API 允许在单个步骤中进行多次 create 、 index 、 update 或 delete 请求。 如果你需要索引一个数据流比如日志事件,它可以排队和索引数百或数千批次。
bulk 与其他的请求体格式稍有不同,如下所示:
{ action: { metadata }}\n
{ request body }\n
{ action: { metadata }}\n
{ request body }\n
action/metadata 行指定哪一个文档做什么操作 。
action 必须是以下选项之一:
- create
如果文档不存在,那么就创建它。 - index
创建一个新文档或者替换一个现有的文档。 - update
部分更新一个文档。 - delete
删除一个文档。 - 案例
curl -XPOST 'localhost:9200/_bulk?pretty' -H 'Content-Type: application/json' -d'
{ "delete": { "_index": "website", "_type": "blog", "_id": "123" }}
{ "create": { "_index": "website", "_type": "blog", "_id": "123" }}
{ "title": "My first blog post" }
{ "index": { "_index": "website", "_type": "blog" }}
{ "title": "My second blog post" }
{ "update": { "_index": "website", "_type": "blog", "_id": "123", "_retry_on_conflict" : 3} }
{ "doc" : {"title" : "My updated blog post"} }
'
四. SpringBoot与Elasticsearch集成
- pom文件中添加添加依赖
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-elasticsearch</artifactId> </dependency> <!-- 解决es no jna warning--> <dependency> <groupId>com.sun.jna</groupId> <artifactId>jna</artifactId> <version>3.0.9</version> </dependency> - application.yml添加配置
spring: data: elasticsearch: cluster-nodes: 127.0.0.1:9300 - 注意:elasticsearch jar版本要与安装的服务版本相容
五. Elasticsearch集群健康状态
5.1 状态说明
- green 最健康得状态,说明所有的分片包括备份都可用
- yellow 基本的分片可用,但是备份不可用(或者是没有备份)
- red 部分的分片可用,表明分片有一部分损坏。此时执行查询部分数据仍然可以查到,遇到这种情况,还是赶快解决比较好
5.2 状态为yellow的解决方法
分片与副本分片
分片用于Elasticsearch在你的集群中分配数据。想象把分片当作数据的容器。文档存储在分片中,然后分片分配给你集群中的节点上。
当你的集群扩容或缩小,Elasticsearch将会自动在你的节点间迁移分片,以使集群保持平衡。
一个分片(shard)是一个最小级别的“工作单元(worker unit)”,它只是保存索引中所有数据的一小片.我们的文档存储和被索引在分片中,但是我们的程序不知道如何直接与它们通信。取而代之的是,他们直接与索引通信.Elasticsearch中的分片分为主分片和副本分片,复制分片只是主分片的一个副本,它用于提供数据的冗余副本,在硬件故障之后提供数据保护,同时服务于像搜索和检索等只读请求,主分片的数量和复制分片的数量都可以通过配置文件配置。但是主切片的数量只能在创建索引时定义且不能修改.相同的分片不会放在同一个节点上。
分片算法
shard = hash(routing) % number_of_primary_shards
routing值是一个任意字符串,它默认是_id但也可以自定义,这个routing字符串通过哈希函数生成一个数字,然后除以主切片的数量得到一个余数(remainder),余数的范围永远是0到number_of_primary_shards – 1,这个数字就是特定文档所在的分片。
这也解释了为什么主切片的数量只能在创建索引时定义且不能修改:如果主切片的数量在未来改变了,所有先前的路由值就失效了,文档也就永远找不到了。
所有的文档API(get、index、delete、bulk、update、mget)都接收一个routing参数,它用来自定义文档到分片的映射。自定义路由值可以确保所有相关文档.比如用户的文章,按照用户账号路由,就可以实现属于同一用户的文档被保存在同一分片上。
单机(空集群)状态为yellow原因
由于我们是单节点部署elasticsearch,而默认的分片副本数目配置为1,而相同的分片不能在一个节点上,所以就存在副本分片指定不明确的问题,所以显示为yellow,我们可以通过在elasticsearch集群上添加一个节点来解决问题,如果你不想这么做,你可以删除那些指定不明确的副本分片(当然这不是一个好办法)但是作为测试和解决办法还是可以尝试的,下面我们试一下删除副本分片的办法
解决方案
curl -XPUT "http://localhost:9200/_settings" -d' { "number_of_replicas" : 0 } '六. 其他
6.1 版本冲突/事务

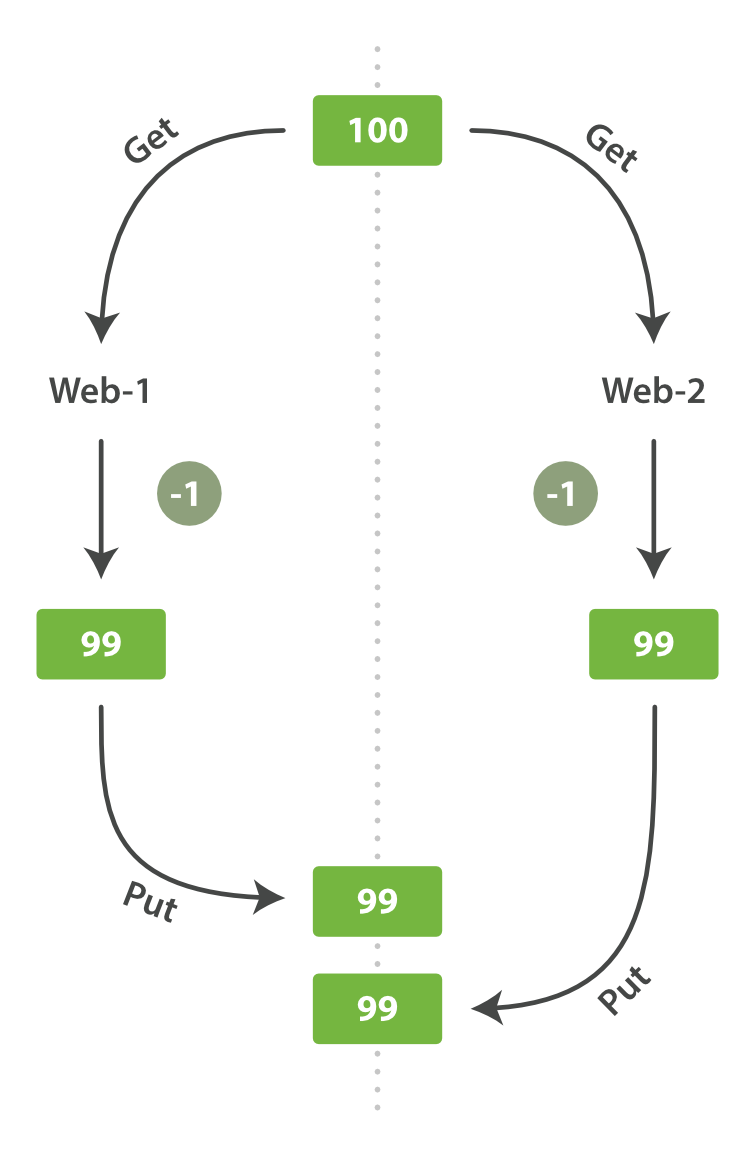
Elasticsearch使用_version来确保所有的改变操作都被正确排序。如果一个旧的版本出现在新版本之后,它就会被忽略掉。
我们可以利用_version的优点来确保我们程序修改的数据冲突不会造成数据丢失。我们可以按照我们的想法来指定_version的数字。如果数字错误,请求就是失败。
实例演示:
- 插入数据
curl -XPOST 'localhost:9200/employee/it/1?pretty' -H 'Content-Type: application/json' -d'
{
"first_name" : "John",
"last_name" : "Smith",
"age" : 25,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
'
- 修改数据
curl -XPUT 'localhost:9200/employee/it/1?pretty' -H 'Content-Type: application/json' -d'
{
"first_name" : "John",
"last_name" : "Smith",
"age" : 25,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
'
- 再次修改数据
curl -XPUT 'localhost:9200/employee/it/1?version=1&pretty' -H 'Content-Type: application/json' -d'
{
"first_name" : "John",
"last_name" : "Smith",
"age" : 25,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
'
异常如下:
{
"error" : {
"root_cause" : [ {
"type" : "version_conflict_engine_exception",
"reason" : "[it][1]: version conflict, current [2], provided [1]",
"shard" : "3",
"index" : "employee"
} ],
"type" : "version_conflict_engine_exception",
"reason" : "[it][1]: version conflict, current [2], provided [1]",
"shard" : "3",
"index" : "employee"
},
"status" : 409
}
