Kafka说明
Apache Kafka® 是一个分布式流媒体平台,这是什么意思呢?
分布式流媒体平台它有三大特性:
- 发布与订阅流媒体数据,类似于消息队列或企业消息传递系统
- 能够容错并持久性存储流媒体数据
- 处理流媒体数据
Kafka通常适用于两大类应用场景:
- 在系统或应用程序之间构建实时数据流管道,使其可靠地获取数据
- 在应用程序中对数据流进行实时转换或响应
要了解Kafka如何做这些事情,让我们深入探讨Kafka的能力。
首先是几个概念:
- Kafka作为一个集群运行在一个或多个可跨多个数据中心的服务器上。
- Kafka集群以称为topics类别存储记录流。
- 每条记录流都由一个键、值和时间戳组成。
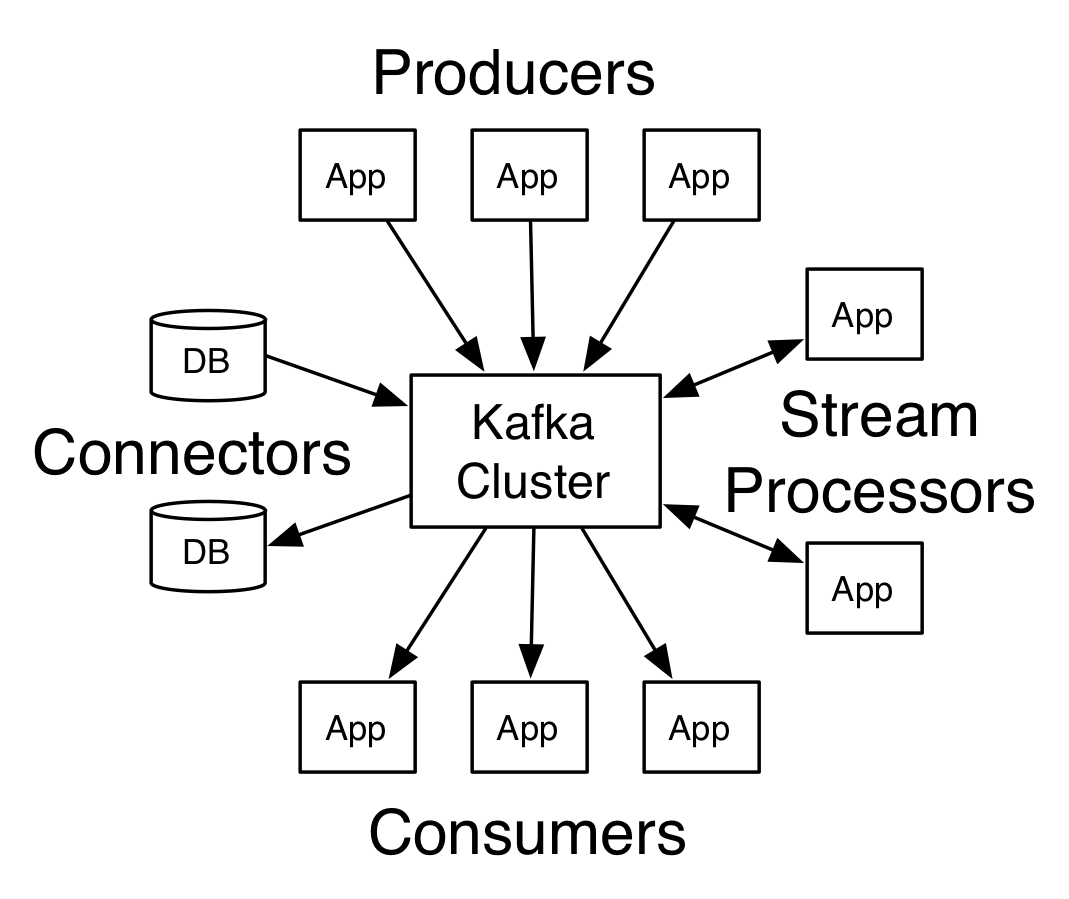
Kafka有四个核心API:
- 生产者(Producer API )允许应用程序发布一条数据记录到一个或更多的Kafka topics。
- 消费者(Consumer API)允许应用程序订阅一个或多个主题,并处理为其生成的记录流。
- 数据流(Streams API)允许应用程序充当流处理器( stream processor),使用来自一个或多个topics输入流,并将输出流生成到一个或多个输出topics,从而有效地将输入流转换为输出流。
- 连接器(Connector API)允许构建并运行可重用的生产者或消费者,将Kafka topics连接到现有的应用程序或数据系统。例如,数据库的连接器可以捕获每个表的更改。
在Kafka中,客户机和服务器之间的通信是通过一种简单、高性能、与语言无关的TCP协议来完成。 此协议已经版本化,并保持与旧版本的向后兼容性。我们为Kafka提供Java客户端,客户端可以使用多语言版本。
Topics and Logs
让我们首先深入探讨Kafka为记录流提供的核心抽象 – topic。
topic是发布记录的类别或源名称。Kafka中的Topics总是多个订阅用户;也就是说,一个topic可以有0个、1个或多个订户订阅者。
对于每个topic,Kafka群集都维护一个分区日志,如下所示:
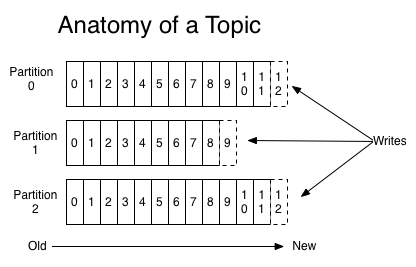 每个分区都是一个有序的,不可变的记录序列,不断附加到一个结构化的日志中。分区中的记录每个都被分配一个 offset 的顺序ID号,它标识分区中的每个记录。
每个分区都是一个有序的,不可变的记录序列,不断附加到一个结构化的日志中。分区中的记录每个都被分配一个 offset 的顺序ID号,它标识分区中的每个记录。
Kafka集群持久地保留所有已发布的记录,无论它们是否已被消耗,可以使用可配置方式设置的过期时间。例如,如果保留策略设置为两天,则在发布记录后的两天内,它可供使用,之后将被丢弃以释放空间。Kafka的性能在数据大小方面实际上是恒定的,因此长时间存储数据不是问题。
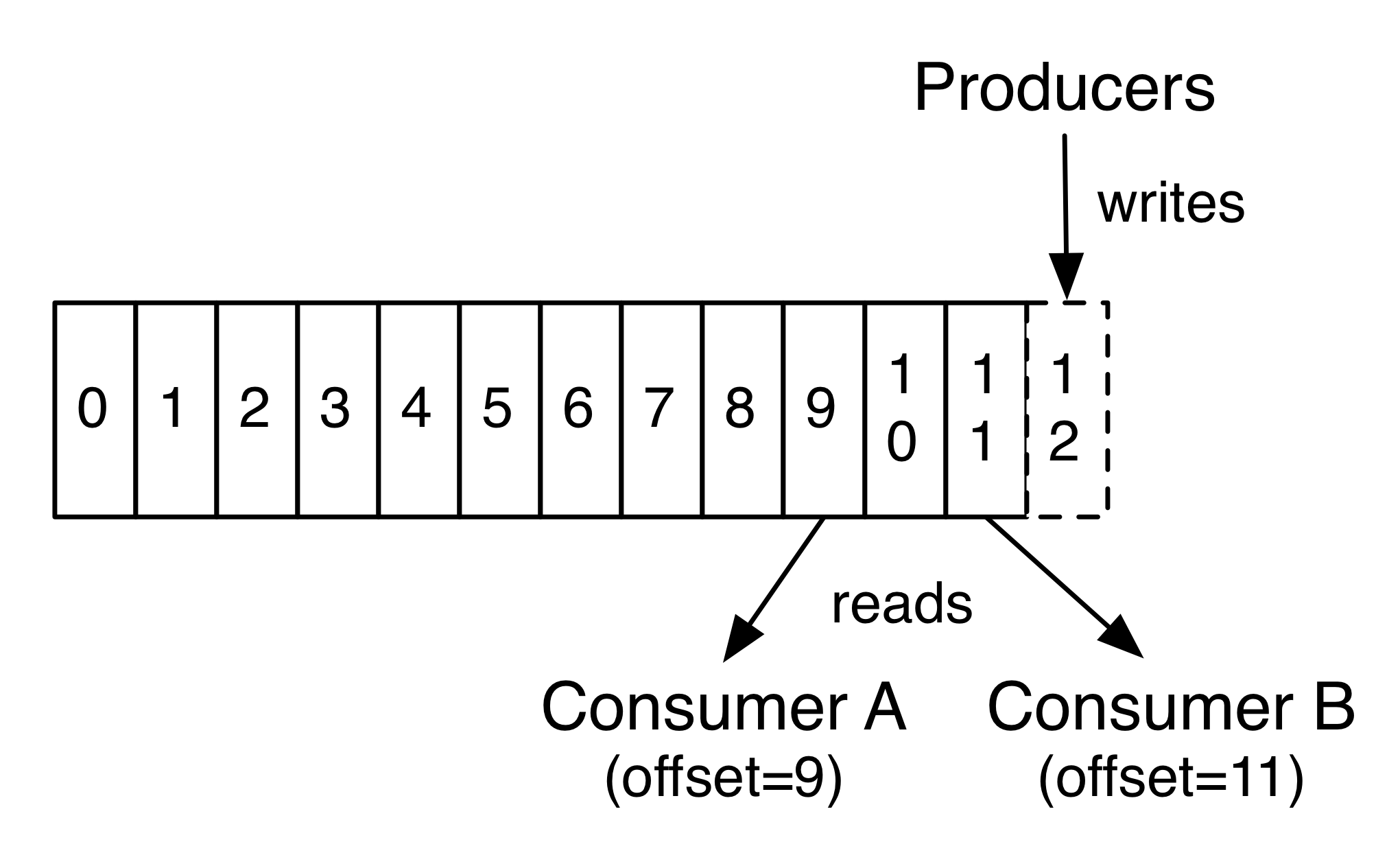 事实上,在消费者的日志中使用偏移量(offset)或分区来保持唯一的元数据。这种偏移(offset)由消费者控制:通常消费者在读取记录时会线性地提高其偏移量(offset),但事实上,由于消费者控制偏移量(offset)的位置,它可以按照自己喜欢的任何顺序消费记录。例如,消费者可以重置为已处理过或较旧的偏移量(offset)以重新处理过去的数据,或者跳到最近的记录并从“现在”开始消费。
事实上,在消费者的日志中使用偏移量(offset)或分区来保持唯一的元数据。这种偏移(offset)由消费者控制:通常消费者在读取记录时会线性地提高其偏移量(offset),但事实上,由于消费者控制偏移量(offset)的位置,它可以按照自己喜欢的任何顺序消费记录。例如,消费者可以重置为已处理过或较旧的偏移量(offset)以重新处理过去的数据,或者跳到最近的记录并从“现在”开始消费。
这些功能组合意味着Kafka消费者非常简单,他们可以来来往往对集群或其他消费者没有太大影响。例如,您可以使用我们的命令行工具“tail”任何主题的内容,而无需更改任何现有消费者所消费的内容。
日志中的分区有多种用途。首先,它们允许日志扩展到超出单个服务器的大小。每个单独的分区必须适合托管它的服务器,但topic可能有许多分区,因此它可以处理任意数量的数据。其次,在一点上他们更像是并行的单元。
分配
日志的分区分布在Kafka集群中的服务器上,每个服务器处理数据并请求分区的共享。每个分区都在可配置数量的服务器上进行复制,以实现容错。
每个分区都有一个服务器充当“领导者(leader)”,0个或多个服务器充当“追随者(followers)”。领导者处理分区的所有读取和写入请求,而关注者被动地复制领导者。如果领导者出现故障,其中一个追随者将自动成为新的领导者。每个服务器都充当其某些分区的领导者和其他服务器的追随者,因此负载在群集中很均衡。
地理复制
Kafka MirrorMaker为群集提供地理复制的支持。使用MirrorMaker,消息跨多个数据中心或云区域进行复制。你可以使用它在active/passive方案中进行备份和恢复; 或者在active/active方案中,按地理的方式,使数据更接近用户,或支持数据位置要求。
生产者
生产者将数据发布到他们选择的topics。生产者负责选择要分配给topic中哪个分区的记录。这可以通过循环方式完成,只是为了平衡负载,或者可以根据一些语义分区功能(例如:基于记录中的某些键)来完成。
消费者
消费者使用 consumer group 名称标记自己,每一个记录都会发布到一个topic中,并传递给每一个订阅的 consumer group 中其中一个消费者。消费者实例可以在同一个进程中,也可以在不同的机器
如果所有消费者实例具有相同的 consumer group,那么记录将在消费者实例上进行负载平衡(只有其中一个能收到消息)。
如果所有消费者实例具有不同的 consumer groups,那么每个记录将使用广播的方式,发送到所有 consumer group 进程。
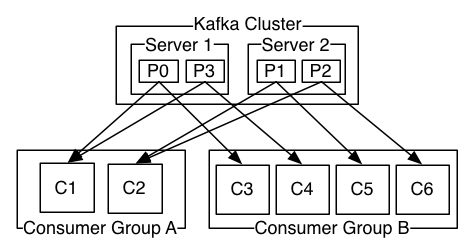 两个服务器Kafka群集,托管四个分区(P0-P3),包含两个 consumer groups。 group A有两个消费者, group B有四个消费者。
两个服务器Kafka群集,托管四个分区(P0-P3),包含两个 consumer groups。 group A有两个消费者, group B有四个消费者。
然而,更常见的是,我们发现topics具有少量的 consumer groups,每个“logical subscriber”一个。每个组由许多用于可伸缩性和容错的消费者实例组成。这只不过是发布 – 订阅语义,其中订阅者是消费者群集而不是单个进程。
在Kafka中实现消费的方式是通过在消费者实例上划分日志中的分区,以便每个实例在任何时间点都是分配的“公平份额”的独占消费者。这个维护组成员身份的过程是由kafka协议动态处理的。如果有新的消费者实例加入该组,他们将从该组的其他成员接管一些分区; 如果实例出现故障,那么其分区将分配给其余消费者实例。
Kafka仅提供分区内记录的总订单,而不是主题中不同分区之间的记录。对于大多数应用程序而言,按分区排序与按键分区数据的能力相结合就足够了。但是,如果需要对记录进行总排序,可以使用只有一个分区的主题来实现,但这将意味着每个 consumer group 只有一个消费者进程。
多租户
您可以将Kafka部署为多租户解决方案。通过配置哪些主题可以生成或使用数据来启用多租户。配额也有运营支持。管理员可以定义和强制执行配额,以控制客户端使用的代理资源。有关更多信息,请参阅安全文档
担保
在高级别Kafka提供以下保证:
- 生产者按顺序将消息发送到特定主题分区。也就是说,如果记录数据M1由与数据M2是由同一个生产者发送,并且首先发送M1,则M1将具有比M2更低的偏移并在日志中更早出现。
- 消费者实例按照它们存储在日志中的顺序查看记录。
- 对于具有复制因子N的主题,我们将容忍最多N-1个服务器故障,而不会丢失任何提交到日志的记录。
下一篇,将Kafka集成到Spring中。
有关Kafka提供的API和功能的更多信息,请参阅官方文档。
