If you’ve dug into any articles on artificial intelligence, you’ve almost certainly run into the term “neural network.” Modeled loosely on the human brain, artificial neural networks enable computers to learn from being fed data.
The efficacy of this powerful branch of machine learning, more than anything else, has been responsible for ushering in a new era of artificial intelligence, ending a long-lived “AI Winter.” Simply put, the neural network may well be one of the most fundamentally disruptive technologies in existence today.
This guide to neural networks aims to give you a conversational level of understanding of deep learning. To this end, we’ll avoid delving into the math and instead rely as much as possible on analogies and animations.
Thinking by brute force
One of the early schools of AI taught that if you load up as much information as possible into a powerful computer and give it as many directions as possible to understand that data, it ought to be able to “think.” This was the idea behind chess computers like IBM’s famous Deep Blue: By exhaustively programming every possible chess move into a computer, as well as known strategies, and then giving it sufficient power, IBM programmers created a machine that, in theory, could calculate every possible move and outcome into the future and pick the sequence of subsequent moves to outplay its opponent. This actually works, as chess masters learned in 1997.*
With this sort of computing, the machine relies on fixed rules that have been painstakingly pre-programmed by engineers — if this happens, then that happens; if this happens, do this — and so it isn’t human-style flexible learning as we know it at all. It’s powerful supercomputing, for sure, but not “thinking” per se.
Teaching machines to learn
Over the past decade, scientists have resurrected an old concept that doesn’t rely on a massive encyclopedic memory bank, but instead on a simple and systematic way of analyzing input data that’s loosely modeled after human thinking. Known as deep learning, or neural networks, this technology has been around since the 1940s, but because of today’s exponential proliferation of data — images, videos, voice searches, browsing habits and more — along with supercharged and affordable processors, it is at last able to begin to fulfill its true potential.
Machines — they’re just like us!
An artificial (as opposed to human) neural network (ANN) is an algorithmic construct that enables machines to learn everything from voice commands and playlist curation to music composition and image recognition.The typical ANN consists of thousands of interconnected artificial neurons, which are stacked sequentially in rows that are known as layers, forming millions of connections. In many cases, layers are only interconnected with the layer of neurons before and after them via inputs and outputs. (This is quite different from neurons in a human brain, which are interconnected every which way.)
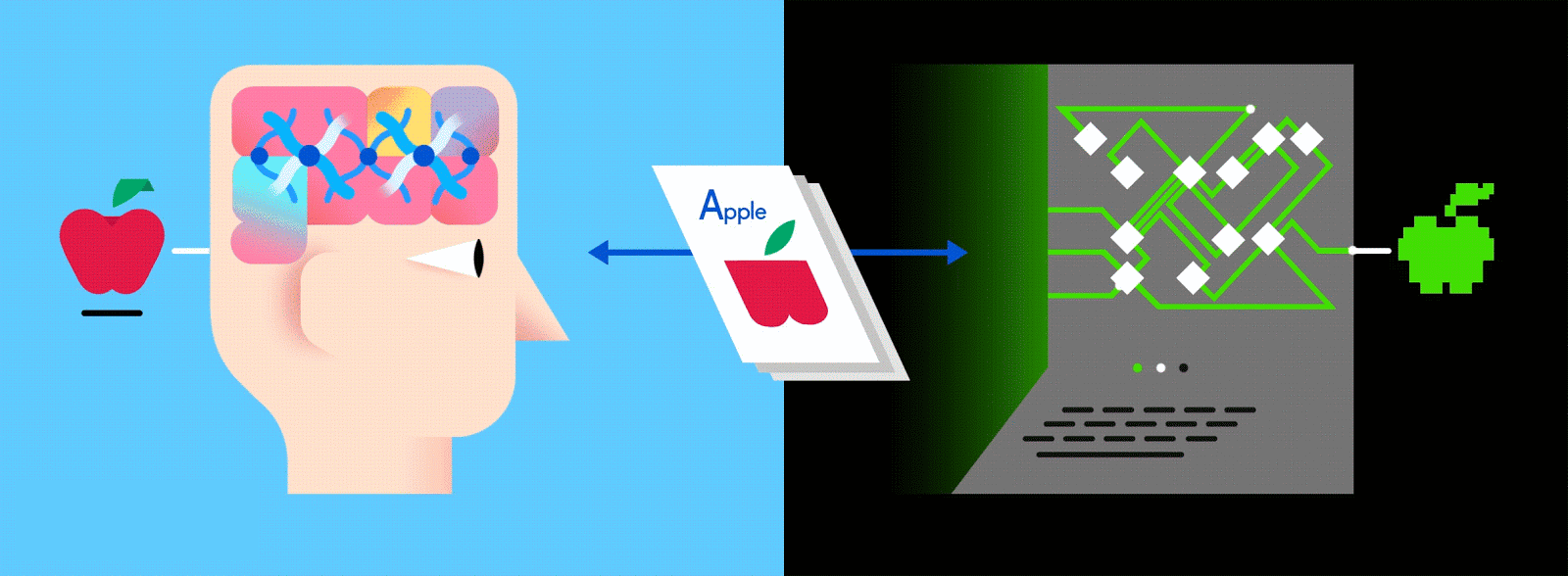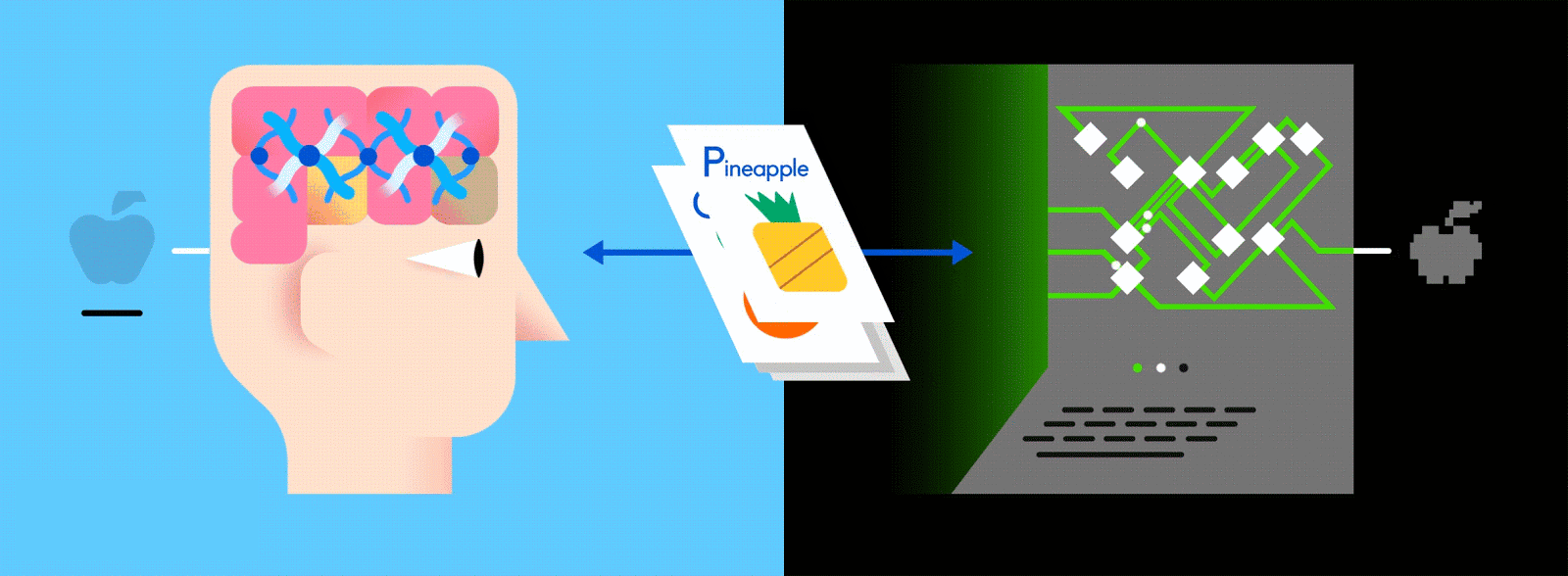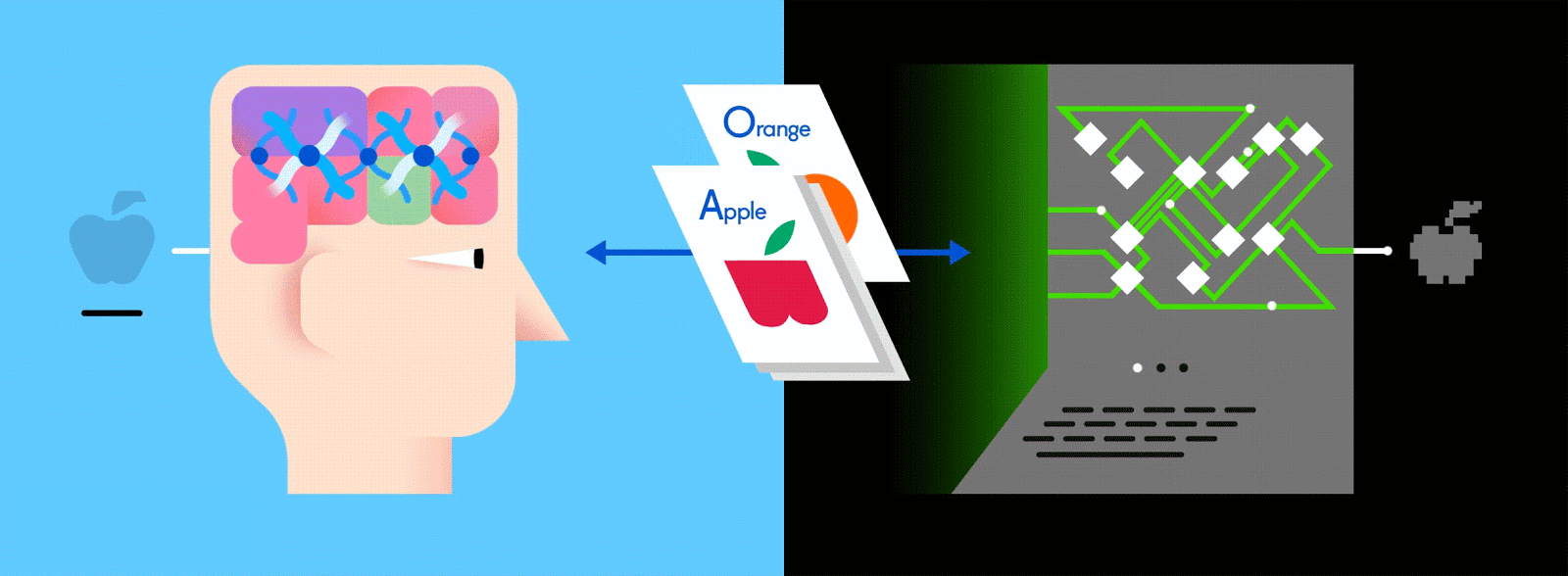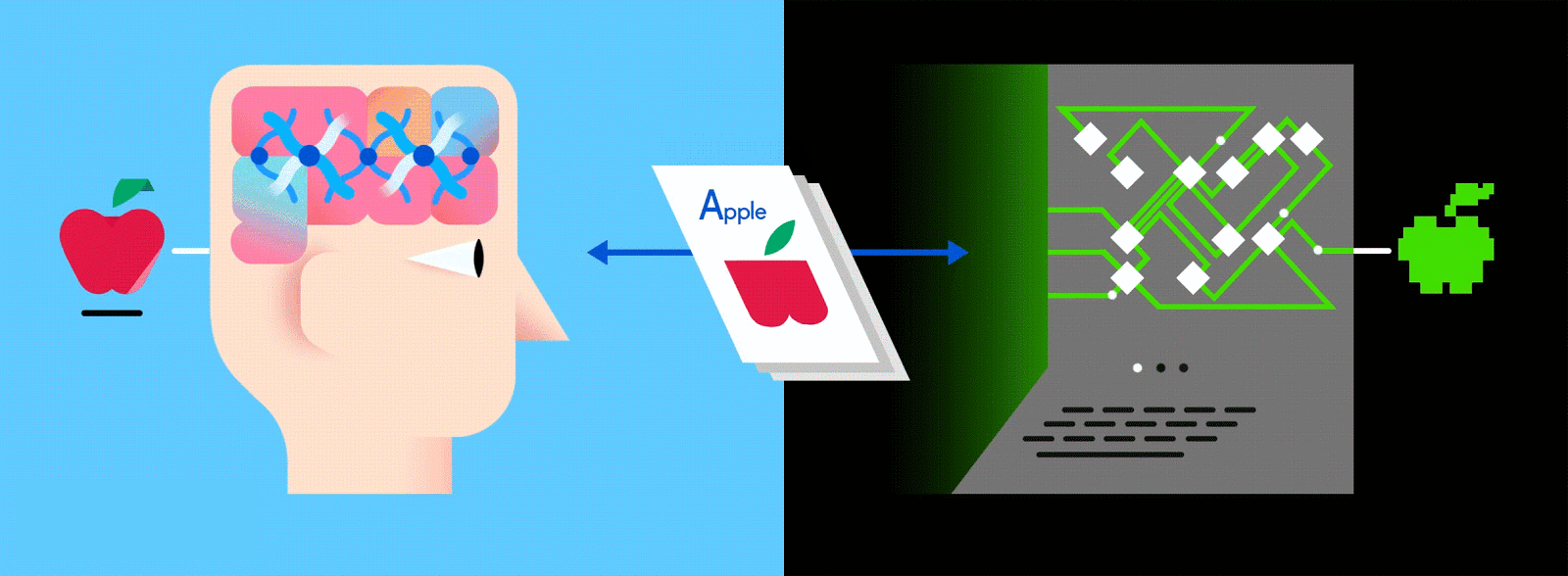
This layered ANN is one of the main ways to go about machine learning today, and feeding it vast amounts of labeled data enables it to learn how to interpret that data like (and sometimes better than) a human.
Just as when parents teach their kids to identify apples and oranges in real life, for computers too, practice makes perfect.
Take, for example, image recognition, which relies on a particular type of neural network known as the convolutional neural network (CNN) — so called because it uses a mathematical process known as convolution to be able to analyze images in non-literal ways, such as identifying a partially obscured object or one that is viewable only from certain angles. (There are other types of neural networks, including recurrent neural networks and feed-forward neural networks, but these are less useful for identifying things like images, which is the example we’re going to use below.)
All aboard the network training
So how do neural networks learn? Let’s look at a very simple, yet effective, procedure called supervised learning. Here, we feed the neural network vast amounts of training data, labeled by humans so that a neural network can essentially fact-check itself as it’s learning.
Let’s say this labeled data consists of pictures of apples and oranges, respectively. The pictures are the data; “apple” and “orange” are the labels, depending on the picture. As pictures are fed in, the network breaks them down into their most basic components, i.e. edges, textures and shapes. As the picture propagates through the network, these basic components are combined to form more abstract concepts, i.e. curves and different colors which, when combined further, start to look like a stem, an entire orange, or both green and red apples.
At the end of this process, the network attempts to make a prediction as to what’s in the picture. At first, these predictions will appear as random guesses, as no real learning has taken place yet. If the input image is an apple, but “orange” is predicted, the network’s inner layers will need to be adjusted.
The adjustments are carried out through a process called backpropagation to increase the likelihood of predicting “apple” for that same image the next time around. This happens over and over until the predictions are more or less accurate and don’t seem to be improving. Just as when parents teach their kids to identify apples and oranges in real life, for computers too, practice makes perfect. If, in your head, you just thought “hey, that sounds like learning,” then you may have a career in AI.
So many layers…
Typically, a convolutional neural network has four essential layers of neurons besides the input and output layers:
- Convolution
- Activation
- Pooling
- Fully connected
Convolution
In the initial convolution layer or layers, thousands of neurons act as the first set of filters, scouring every part and pixel in the image, looking for patterns. As more and more images are processed, each neuron gradually learns to filter for specific features, which improves accuracy.
In the case of apples, one filter might be focused on finding the color red, while another might be looking for rounded edges and yet another might be identifying thin, stick-like stems. If you’ve ever had to clean out a cluttered basement to prepare for a garage sale or a big move — or worked with a professional organizer — then you know what it is to go through everything and sort it into different-themed piles (books, toys, electronics, objets d’art, clothes). That’s sort of what a convolutional layer does with an image by breaking it down into different features.
One advantage of neural networks is that they are capable of learning in a nonlinear way.
What’s particularly powerful — and one of the neural network’s main claims to fame — is that unlike earlier AI methods (Deep Blue and its ilk), these filters aren’t hand designed; they learn and refine themselves purely by looking at data.
The convolution layer essentially creates maps — different, broken-down versions of the picture, each dedicated to a different filtered feature — that indicate where its neurons see an instance (however partial) of the color red, stems, curves and the various other elements of, in this case, an apple. But because the convolution layer is fairly liberal in its identifying of features, it needs an extra set of eyes to make sure nothing of value is missed as a picture moves through the network.
Activation
One advantage of neural networks is that they are capable of learning in a nonlinear way, which, in mathless terms, means they are able to spot features in images that aren’t quite as obvious — pictures of apples on trees, some of them under direct sunlight and others in the shade, or piled into a bowl on a kitchen counter. This is all thanks to the activation layer, which serves to more or less highlight the valuable stuff — both the straightforward and harder-to-spot varieties.
In the world of our garage-sale organizer or clutter consultant, imagine that from each of those separated piles of things we’ve cherry-picked a few items — a handful of rare books, some classic t-shirts from our college days to wear ironically — that we might want to keep. We stick these “maybe” items on top of their respective category piles for another consideration later.
Pooling
All this “convolving” across an entire image generates a lot of information, and this can quickly become a computational nightmare. Enter the pooling layer, which shrinks it all into a more general and digestible form. There are many ways to go about this, but one of the most popular is “max pooling,” which edits down each feature map into a Reader’s Digest version of itself, so that only the best examples of redness, stem-ness or curviness are featured.
In the garage spring cleaning example, if we were using famed Japanese clutter consultant Marie Kondo’s principles, our pack rat would have to choose only the things that “spark joy” from the smaller assortment of favorites in each category pile, and sell or toss everything else. So now we still have all our piles categorized by type of item, but only consisting of the items we actually want to keep; everything else gets sold. (And this, by the way, ends our de-cluttering analogy to help describe the filtering and downsizing that goes on inside a neural network.)
At this point, a neural network designer can stack subsequent layered configurations of this sort — convolution, activation, pooling — and continue to filter down images to get higher-level information. In the case of identifying an apple in pictures, the images get filtered down over and over, with initial layers showing just barely discernable parts of an edge, a blip of red or just the tip of a stem, while subsequent, more filtered layers will show entire apples. Either way, when it’s time to start getting results, the fully connected layer comes into play.
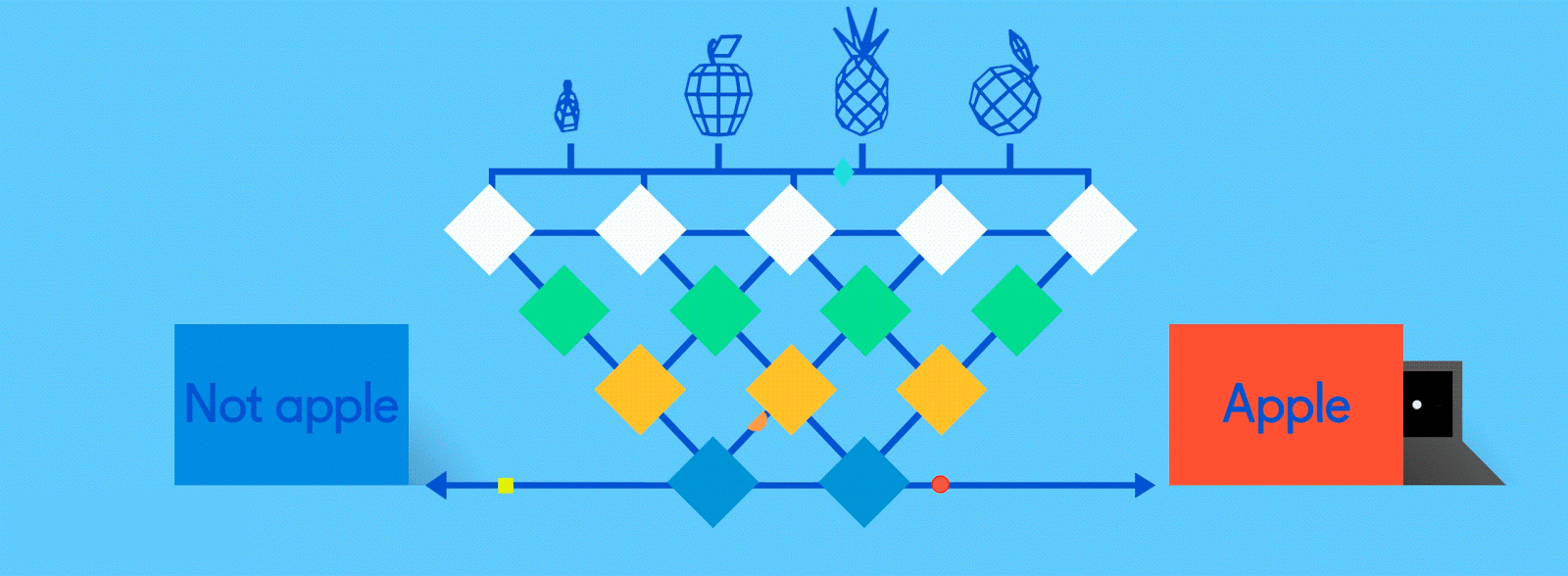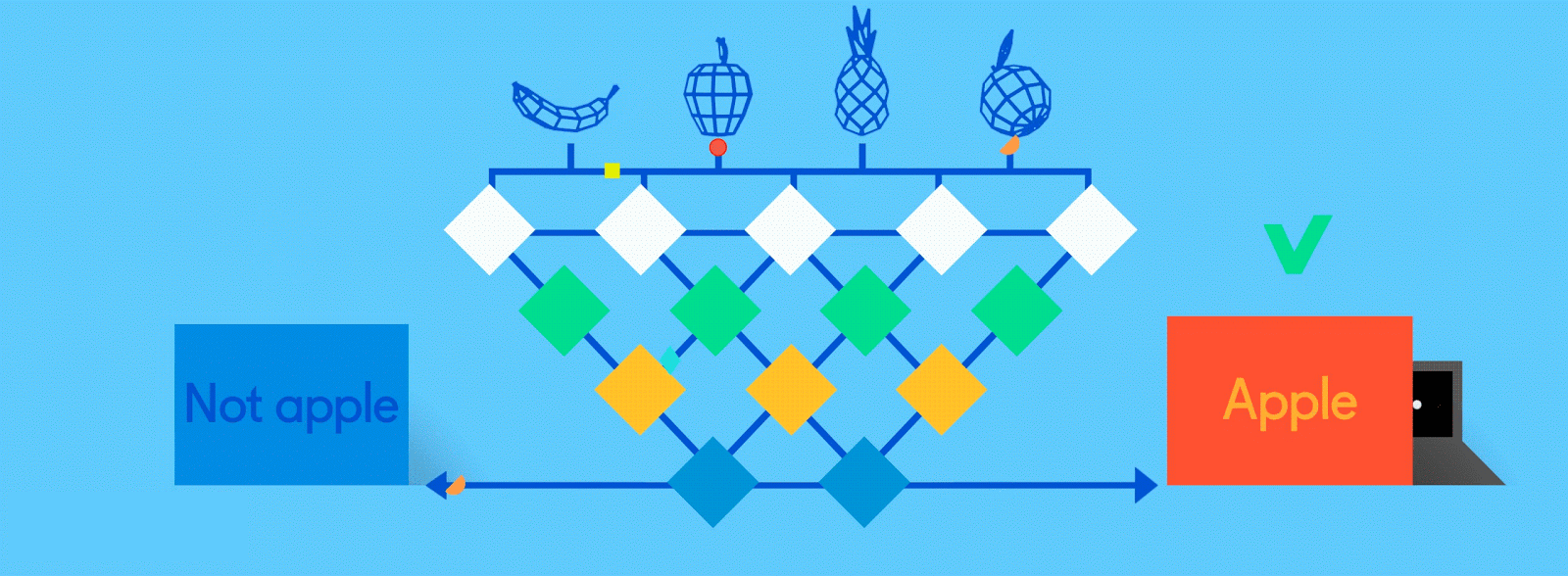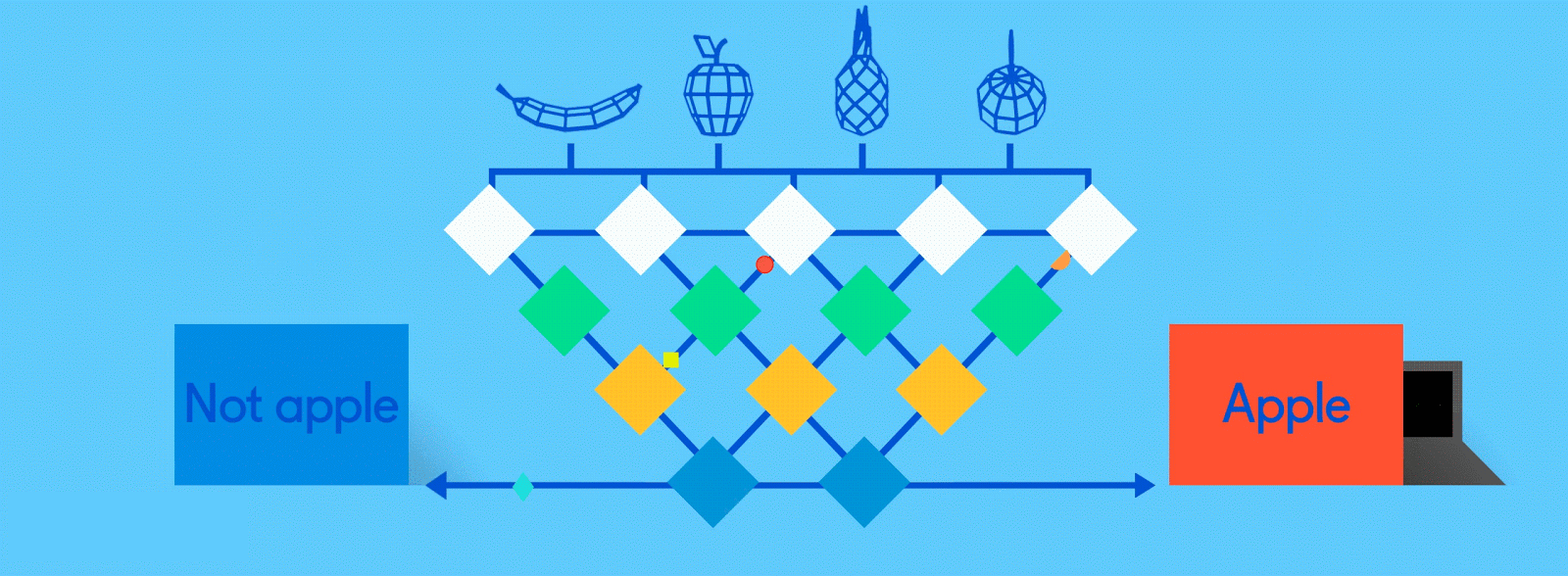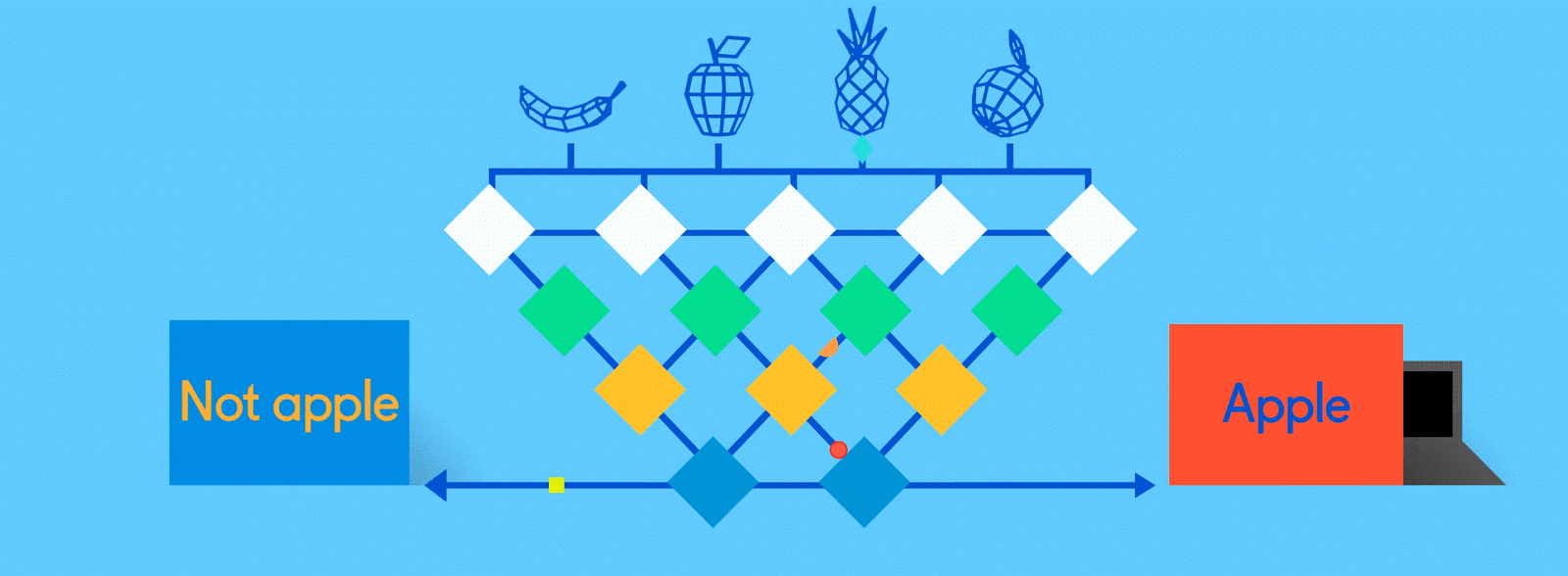
Fully connected
Now it’s time to start getting answers. In the fully connected layer, each reduced, or “pooled,” feature map is “fully connected” to output nodes (neurons) that represent the items the neural network is learning to identify. If the network is tasked with learning how to spot cats, dogs, guinea pigs and gerbils, then it’ll have four output nodes. In the case of the neural network we’ve been describing, it’ll just have two output nodes: one for “apples” and one for “oranges.”
If the picture that has been fed through the network is of an apple, and the network has already undergone some training and is getting better with its predictions, then it’s likely that a good chunk of the feature maps contain quality instances of apple features. This is where these final output nodes start to fulfill their destiny, with a reverse election of sorts.
Tweaks and adjustments are made to help each neuron better identify the data at every level.
The job (which they’ve learned “on the job”) of both the apple and orange nodes is essentially to “vote” for the feature maps that contain their respective fruits. So, the more the “apple” node thinks a particular feature map contains “apple” features, the more votes it sends to that feature map. Both nodes have to vote on every single feature map, regardless of what it contains. So in this case, the “orange” node won’t send many votes to any of the feature maps, because they don’t really contain any “orange” features. In the end, the node that has sent the most votes out — in this example, the “apple” node — can be considered the network’s “answer,” though it’s not quite that simple.
Because the same network is looking for two different things — apples and oranges — the final output of the network is expressed as percentages. In this case, we’re assuming that the network is already a bit down the road in its training, so the predictions here might be, say, 75 percent “apple” and 25 percent “orange.” Or, if it’s earlier in the training, it might be more inaccurate and determine that it’s 20 percent “apple” and 80 percent “orange.” Oops.
Source: GumGum
If at first you don’t succeed, try, try, try again
So, in its early stages, the neural network spits out a bunch of wrong answers in the form of percentages. The 20 percent “apple” and 80 percent “orange” prediction is clearly wrong, but since this is supervised learning with labeled training data, the network is able to figure out where and how that error occurred through a system of checks and balances known as backpropagation.
Now, this is a mathless explanation, so suffice it to say that backpropagation sends feedback to the previous layer’s nodes about just how far off the answers were. That layer then sends the feedback to the previous layer, and on and on like a game of telephone until it’s back at convolution. Tweaks and adjustments are made to help each neuron better identify the data at every level when subsequent images go through the network.
This process is repeated over and over until the neural network is identifying apples and oranges in images with increasing accuracy, eventually ending up at 100 percent correct predictions — though many engineers consider 85 percent to be acceptable. And when that happens, the neural network is ready for prime time and can start identifying apples in pictures professionally.
*This is different than Google’s AlphaGo which used a self-learned neural net to evaluate board positions and ultimately beat a human at Go, versus Deep Blue, which used a hard-coded function written by a human.
译文:
现在谈人工智能已经绕不开“神经网络”这个词了。人造神经网络粗线条地模拟人脑,使得计算机能够从数据中学习。
机器学习这一强大的分支结束了 AI 的寒冬,迎来了人工智能的新时代。简而言之,神经网络可能是今天最具有根本颠覆性的技术。
看完这篇神经网络的指南,你也可以和别人聊聊深度学习了。为此,我们将尽量不用数学公式,而是尽可能用打比方的方法,再加一些动画来说明。
强力思考
AI 的早期流派之一认为,如果您将尽可能多的信息加载到功能强大的计算机中,并尽可能多地提供方法来了解这些数据,那么计算机就应该能够“思考”。比如 IBM 著名的国际象棋 AI Deep Blue 背后就是这么一个思路:通过对棋子可能走出的每一步进行编程,再加上足够的算力,IBM 程序员创建了一台机器,理论上可以计算出每一个可能的动作和结果,以此来击败对手。
通过这种计算,机器依赖于工程师精心预编程的固定规则——如果发生了 A,那么就会发生 B ; 如果发生了 C,就做 D——这并不是如人类一样的灵活学习。当然,它是强大的超级计算,但不是“思考”本身。
教机器学习
在过去十年中,科学家已经复活了一个旧概念,不再依赖大型百科全书式记忆库,而是框架性地进行模拟人类思维,以简单而系统的方式分析输入数据。 这种技术被称为深度学习或神经网络,自20世纪40年代以来一直存在,但是由于今天数据的大量增长—— 图像、视频、语音搜索、浏览行为等等——以及运算能力提升而成本下降的处理器,终于开始显示其真正的威力。
机器——它们和我们很像
人工神经网络(ANN)是一种算法结构,使得机器能够学习一切,从语音命令、播放列表到音乐创作和图像识别。典型的 ANN 由数千个互连的人造神经元组成,它们按顺序堆叠在一起,以称为层的形式形成数百万个连接。在许多情况下,层仅通过输入和输出与它们之前和之后的神经元层互连。(这与人类大脑中的神经元有很大的不同,它们的互连是全方位的。)

这种分层的 ANN 是今天机器学习的主要方式之一,通过馈送其大量的标签数据,可以帮助它学习如何解读数据(有时甚至比人类做得更好)。
以图像识别为例,它依赖于称为卷积神经网络(CNN)的特定类型的神经网络,因为它使用称为卷积的数学过程来以非文字的方式分析图像, 例如识别部分模糊的对象或仅从某些角度可见的对象。 (还有其他类型的神经网络,包括循环神经网络和前馈神经网络,但是这些神经网络对于识别诸如图像的东西不太有用,下面我们会用示例来说明)
神经网络的训练过程
那么神经网络到底是如何学习的? 让我们看一个非常简单但有效的流程,它叫作监督学习。我们为神经网络提供了大量的人类标记的训练数据,以便神经网络可以进行基本的自我检查。
假设这个标签数据分别由苹果和橘子的图片组成。照片是数据;“苹果”和“橘子”是标签。当输入图像数据时,网络将它们分解为最基本的组件,即边缘、纹理和形状。当图像数据在网络中传递时,这些基本组件被组合以形成更抽象的概念,即曲线和不同的颜色,这些元素在进一步组合时,就开始看起来像茎、整个的橘子,或是绿色和红色的苹果。
在这个过程的最后,网络试图对图片中的内容进行预测。首先,这些预测将显示为随机猜测,因为真正的学习还未发生。如果输入图像是苹果,但预测为“橘子”,则网络的内部层需要被调整。
调整的过程称为反向传播,以增加下一次将同一图像预测成“苹果”的可能性。这一过程持续进行,直到预测的准确度不再提升。正如父母教孩子们在现实生活中认苹果和橘子一样,对于计算机来说,训练造就完美。如果你现在已经觉得“这不就是学习吗?”,那你可能很适合搞人工智能。
很多很多层……
通常,卷积神经网络除了输入和输出层之外还有四个基本的神经元层:
卷积层(Convolution)
激活层(Activation)
池化层(Pooling)
完全连接层(Fully connected)
卷积层
在最初的卷积层中,成千上万的神经元充当第一组过滤器,搜寻图像中的每个部分和像素,找出模式(pattern)。随着越来越多的图像被处理,每个神经元逐渐学习过滤特定的特征,这提高了准确性。
比如图像是苹果,一个过滤器可能专注于发现“红色”这一颜色,而另一个过滤器可能会寻找圆形边缘,另一个过滤器则会识别细细的茎。如果你要清理混乱的地下室,准备在车库搞个大销售,你就能理解把一切按不同的主题分类是什么意思了(玩具、电子产品、艺术品、衣服等等)。 卷积层就是通过将图像分解成不同的特征来做这件事的。
特别强大的是,神经网络赖以成名的绝招与早期的 AI 方法(比如 Deep Blue 中用到的)不同,这些过滤器不是人工设计的。他们纯粹是通过查看数据来学习和自我完善。
卷积层创建了不同的、细分的图像版本,每个专用于不同的过滤特征——显示其神经元在哪里看到了红色、茎、曲线和各种其他元素的实例(但都是部分的) 。但因为卷积层在识别特征方面相当自由,所以需要额外的一双眼睛,以确保当图片信息在网络中传递时,没有任何有价值的部分被遗漏。
神经网络的一个优点是它们能够以非线性的方式学习。如果不用数学术语解释,它们的意思是能够发现不太明显的图像中的特征——树上的苹果,阳光下的,阴影下的,或厨房柜台的碗里的。这一切都要归功于于激活层,它或多或少地突出了有价值的东西——一些既明了又难以发现的属性。
在我们的车库大甩卖中,想像一下,从每一类东西里我们都挑选了几件珍贵的宝物:书籍,大学时代的经典 T 恤。要命的是,我们可能还不想扔它们。我们把这些“可能”会留下的物品放在它们各自的类别之上,以备再考虑。
池化层
整个图像中的这种“卷积”会产生大量的信息,这可能会很快成为一个计算噩梦。进入池化层,可将其全部缩小成更通用和可消化的形式。有很多方法可以解决这个问题,但最受欢迎的是“最大池”(Max Pooling),它将每个特征图编辑成自己的“读者文摘”版本,因此只有红色、茎或曲线的最好样本被表征出来。
在车库春季清理的例子中,如果我们使用著名的日本清理大师 Marie Kondo 的原则,将不得不从每个类别堆中较小的收藏夹里选择“激发喜悦”的东西,然后卖掉或处理掉其他东西。 所以现在我们仍然按照物品类型来分类,但只包括实际想要保留的物品。其他一切都卖了。
这时,神经网络的设计师可以堆叠这一分类的后续分层配置——卷积、激活、池化——并且继续过滤图像以获得更高级别的信息。在识别图片中的苹果时,图像被一遍又一遍地过滤,初始层仅显示边缘的几乎不可辨别的部分,比如红色的一部分或仅仅是茎的尖端,而随后的更多的过滤层将显示整个苹果。无论哪种方式,当开始获取结果时,完全连接层就会起作用。

完全连接层
现在是时候得出结果了。在完全连接层中,每个削减的或“池化的”特征图“完全连接”到表征了神经网络正在学习识别的事物的输出节点(神经元)上。 如果网络的任务是学习如何发现猫、狗、豚鼠和沙鼠,那么它将有四个输出节点。 在我们描述的神经网络中,它将只有两个输出节点:一个用于“苹果”,一个用于“橘子”。
如果通过网络馈送的图像是苹果,并且网络已经进行了一些训练,且随着其预测而变得越来越好,那么很可能一个很好的特征图块就是包含了苹果特征的高质量实例。 这是最终输出节点实现使命的地方,反之亦然。
“苹果”和“橘子”节点的工作(他们在工作中学到的)基本上是为包含其各自水果的特征图“投票”。因此,“苹果”节点认为某图包含“苹果”特征越多,它给该特征图的投票就越多。两个节点都必须对每个特征图进行投票,无论它包含什么。所以在这种情况下,“橘子”节点不会向任何特征图投很多票,因为它们并不真正包含任何“橘子”的特征。最后,投出最多票数的节点(在本例中为“苹果”节点)可以被认为是网络的“答案”,尽管事实上可能不那么简单。
因为同一个网络正在寻找两个不同的东西——苹果和橘子——网络的最终输出以百分比表示。在这种情况下,我们假设网络在训练中表现已经有所下降了,所以这里的预测可能就是75%的“苹果”,25%的“橘子”。或者如果是在训练早期,可能会更加不正确,它可能是20%的“苹果”和80%的“橘子”。这可不妙。

如果一开始没成功,再试,再试…
所以,在早期阶段,神经网络可能会以百分比的形式给出一堆错误的答案。 20%的“苹果”和80%的“橘子”,预测显然是错误的,但由于这是使用标记的训练数据进行监督学习,所以网络能够通过称为“反向传播”的过程来进行系统调整。
避免用数学术语来说,反向传播将反馈发送到上一层的节点,告诉它答案差了多少。然后,该层再将反馈发送到上一层,再传到上一层,直到它回到卷积层,来进行调整,以帮助每个神经元在随后的图像在网络中传递时更好地识别数据。
这个过程一直反复进行,直到神经网络以更准确的方式识别图像中的苹果和橘子,最终以100%的正确率预测结果——尽管许多工程师认为85%是可以接受的。这时,神经网络已经准备好了,可以开始真正识别图片中的苹果了。
