一、Hadoop集群安装前的准备
基础环境
四台Centos6.5
IP地址:
192.168.174.128
192.168.174.129
192.168.174.130
192.168.174.131
四台主机新建hadoop用户并实现ssh免密登陆
iptables关闭和selinux为disabled1.修改主机名和ip地址映射
为了后面操作方便,修改主机名分别为hadoop01、hadoop02、hadoop03、hadoop04。修改主机名只需修改/etc/sysconfig/network文件hostname行即可,这里博主不再复述。然后修改/etc/hosts文件,将ip地址和主机名的映射写入进去,这样,后面其它主机就可根据主机名去对应ip地址。

2.安装JDK
Hadoop的核心组成之一MapReduce是基于java的,因此需要配置基本的java环境。JDK安装十分简单,前面也多次提到。下载jdk安装包,解压jdk到指定目录。
tar -zxvf jdk-8u181-linux-x64.tar.gz -C /usr/local/java修改环境变量,进入/etc/profile
export JAVA_HOME=/usr/local/java/jdk1.8.0_181
export PATH=$PATH:$JAVA_HOME/bin重新加载环境变量生效。JDK需在四个节点都安装配置
3.Zookeeper安装配置
Zookeeper是负责协调Hadoop一致性,是Hadoop实现HA的不可或缺的组件。根据Zookeeper的工作机制,需要在奇数个节点安装Zookeeper。本文在hadoop01、hadoop02、hadoop03三个节点安装Zookeeper。
下载zookeeper安装包,解压zookeeper安装包
设置环境变量,修改/etc/profile
export ZOOKEEPER_HOME=/usr/local/zookeeper/zookeeper-3.4.6
export PATH=$PATH:$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin重新加载环境变量生效
进入zookeeper解压目录下的conf目录下,修改配置文件zoo.cfg,一开始并没有zoo.cfg文件,拷贝zoo_sample.cfg文件重命名为zoo.cfg即可。

创建相应的data目录及datalog目录
mkdir -p /opt/zookeeper/datalog在每个data目录下新建myid文件,hadoop01的myid文件写入1,hadoop02的myid文件写入2,即server.后的数字。另外注意给/opt/zookeeper目录及其子目录给hadoop用户读写操作权限,因为后面使用zookeeper时是以hadoop用户使用的。
到这里zookeeper基本安装配置完成,以hadoop用户启动zookeeper服务
zkServer.sh start查看zookeeper状态
zkServer.sh status二、Hadoop安装配置
下载hadoop安装包,解压hadoop安装包
注意解压后的目录user和group应该为hadoop,道理与前面zookeeper一样,在Hadoop使用过程中使用者是hadoop用户。
设置环境变量,修改配置文件/etc/profile
export HADOOP_HOME=/usr/local/hadoop-2.6.4
export PATH=$PATH:$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin注意hadoop需要配置bin和sbin,不然后面许多命令无法使用。重新加载环境变量生效。
然后就是修改hadoop的配置文件,进入hadoop安装目录下的etc/hadoop目录下,修改配置文件:hadoop-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml,其中配置文件mapred-site.xml在该目录下有一个样本mapred-site.xml.template,复制该文件重命名为mapred-site.xml即可。
修改配置文件hadoop-env.sh。主要是配置java目录
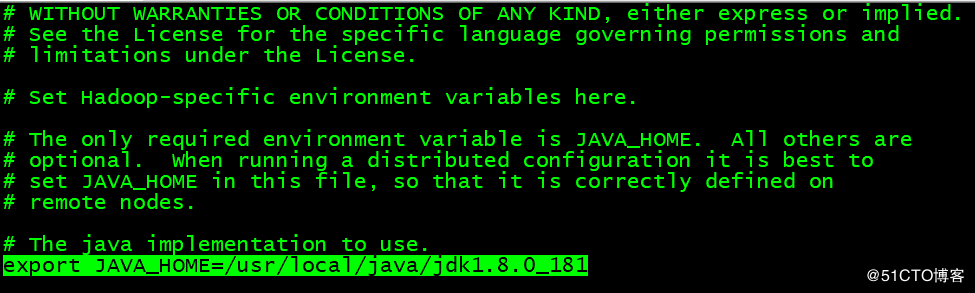
修改配置文件core-site.xml
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://jsj/</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hdpdata</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value>
</property>
</configuration>修改配置文件hdfs-site.xml,从配置文件名也可知这是关于HDFS的配置。
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.nameservices</name>
<value>jsj</value>
</property>
<property>
<name>dfs.ha.namenodes.jsj</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.jsj.nn1</name>
<value>hadoop01:9000</value>
</property>
<property>
<name>dfs.namenode.rpc-address.jsj.nn2</name>
<value>hadoop02:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.jsj.nn1</name>
<value>hadoop01:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.jsj.nn2</name>
<value>hadoop02:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop01:8485;hadoop02:8485;hadoop03:8485/jsj</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/journaldata</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.jsj</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>修改配置文件mapred-site.xml,即MapReduce相关配置。
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop03:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop03:19888</value>
</property>
</configuration>修改配置文件yarn-site.xml。yarn平台的相关配置
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>abc</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop01</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop02</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>最后修改slaves文件
hadoop02
hadoop03
hadoop04至此,Hadoop集群相关配置文件配置完成,在hadoop01、hadoop02、hadoop03、hadoop04四个节点都完成相关配置。
配置文件修改完成并不代表Hadoop安装结束,还需要几个操作才能正常使用。
在hadoop01、hadoop02、hadoop03启动zookeeper服务。
zkServer.sh start在hadoop01、hadoop02、hadoop03启动journalnode
hadoop-daemon.sh start journalnode格式化hdfs,hadoop01执行
hdfs namenode -format然后查看hadoop安装目录确保hdpdata和journaldata在hadoop01和hadoop02都有。没有从一个节点拷贝到另一个节点。
在hadoop01启动namenode
hadoop-daemon.sh start namenode在Hadoop02执行
hdfs namenode -bootstrapStandby格式化zkfc,Hadoop01执行
hdfs zkfc -formatZk在hadoop01启动HDFS
start-dfs.sh完成以上操作后,Hadoop应该可以正常对外做出服务。在浏览器输入hadoop01的ip地址,端口号为50070,查看HDFS的web界面是否正常对外做出服务。
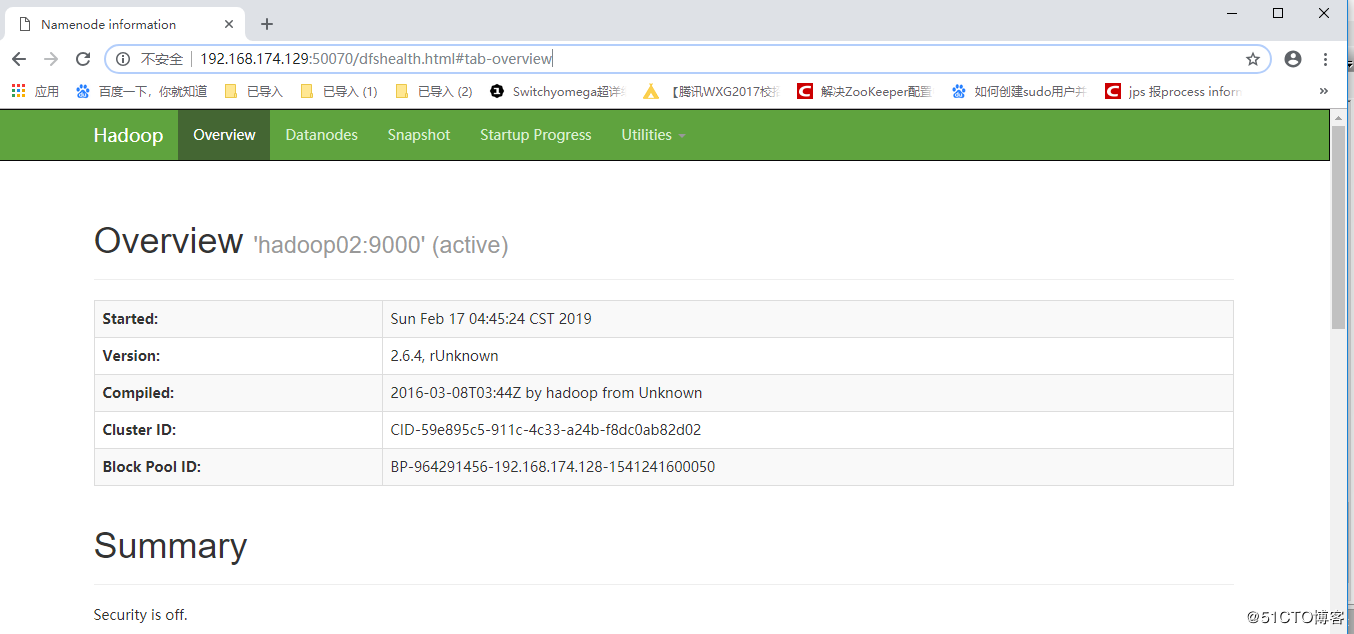
在hadoop01和hadoop02启动yarn平台
start-yarn.sh访问hadoop01的ip地址的8088端口,查看yarn平台是否正常对外做出服务。
Hadoop安装配置完成,关于配置文件的解释后期有时间再加上去。本文使用的安装包是在学习过程老师给的,Hadoop是开源的,相信相关安装包不难找到。
注:转自https://blog.51cto.com/13917261/2364868,原因是觉得写的不错。

近期评论