一、安装zookeeper
1.下载安装包:http://zookeeper.apache.org/releases.html#download;
2.进入Zookeeper设置目录,笔者D:\kafka\zookeeper-3.4.11\conf;
3. 将“zoo_sample.cfg”重命名为“zoo.cfg” ;
3. 编辑zoo.cfg配置文件;
4. 找到并编辑
dataDir=/tmp/zookeeper 并更改成您当前的路径;
5. 系统环境变量:
a. 在系统变量中添加ZOOKEEPER_HOME = D:\kafka\zookeeper-3.4.11
b. 编辑path系统变量,添加为路径%ZOOKEEPER_HOME%\bin;
6. 在zoo.cfg文件中修改默认的Zookeeper端口(默认端口2181);
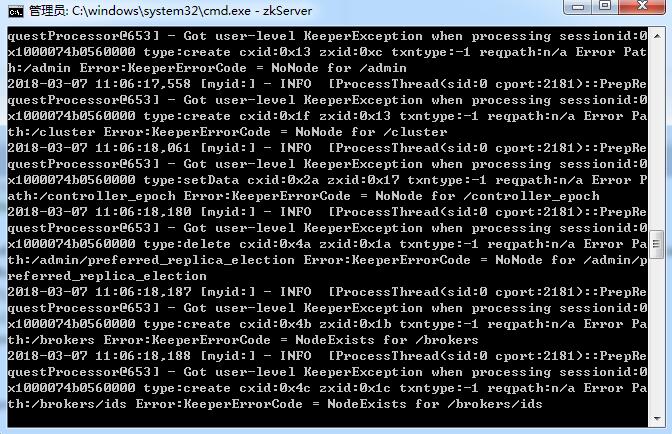
7.打开新的cmd,输入zkServer,运行Zookeeper;
出现如下图片表示成功:
二、安装并运行Kafka
1.下载Kafka:http://kafka.apache.org/downloads.html
2. 进入Kafka配置目录,D:\kafka\kafka_2.12-1.0.1\config;
3. 编辑文件“server.properties” ;
4. 找到并编辑log.dirs=/tmp/kafka-logs 改成您当前可用的目录;
5. 找到并编辑zookeeper.connect=localhost:2181;
6. Kafka会按照默认,在9092端口上运行,并连接zookeeper的默认端口:2181。
运行Kafka代码:.\bin\windows\kafka-server-start.bat .\config\server.properties
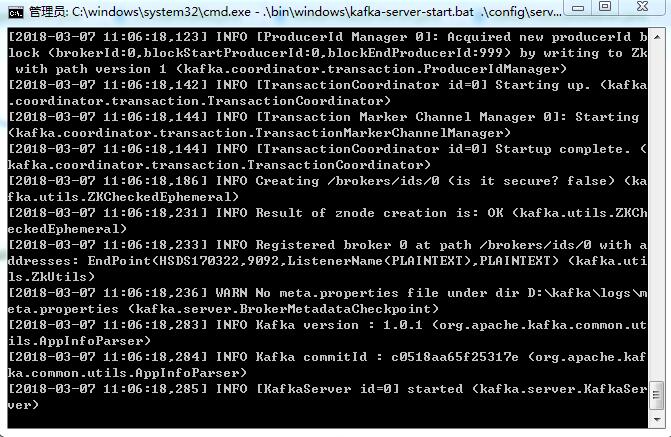
注:请确保在启动Kafka服务器前,Zookeeper实例已经准备好并开始运行。
三、Kafka代码的实现
1.生产者配置文件:
@Bean
public Map<String,Object> getDefaultFactoryArg(){
Map<String,Object> arg = new HashMap<>();
arg.put("bootstrap.servers",ConstantKafka.KAFKA_SERVER);
arg.put("group.id","100");
arg.put("retries","1");
arg.put("batch.size","16384");
arg.put("linger.ms","1");
arg.put("buffer.memory","33554432");
arg.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
arg.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
arg.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
arg.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
return arg;
}
@Bean
public DefaultKafkaProducerFactory defaultKafkaProducerFactory(){
DefaultKafkaProducerFactory factory = new DefaultKafkaProducerFactory(this.getDefaultFactoryArg());
return factory;
}
@Bean
public KafkaTemplate kafkaTemplate(){
KafkaTemplate template = new KafkaTemplate(defaultKafkaProducerFactory());
template.setDefaultTopic(ConstantKafka.KAFKA_TOPIC1);
template.setProducerListener(kafkaProducerListener());
return template;
}
@Bean
public KafkaProducerListener kafkaProducerListener(){
KafkaProducerListener listener = new KafkaProducerListener();
return listener;
}
2.消费者配置文件:
@Bean
public Map<String,Object> getDefaultArgOfConsumer(){
Map<String,Object> arg = new HashMap<>();
arg.put("bootstrap.servers",ConstantKafka.KAFKA_SERVER);
arg.put("group.id","100");
arg.put("enable.auto.commit","false");
arg.put("auto.commit.interval.ms","1000");
arg.put("auto.commit.interval.ms","15000");
arg.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
arg.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
arg.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
arg.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
return arg;
}
@Bean
public DefaultKafkaConsumerFactory defaultKafkaConsumerFactory(){
DefaultKafkaConsumerFactory factory = new DefaultKafkaConsumerFactory(getDefaultArgOfConsumer());
return factory;
}
@Bean
public KafkaConsumerMessageListener kafkaConsumerMessageListener(){
KafkaConsumerMessageListener listener = new KafkaConsumerMessageListener();
return listener;
}
/**
* 监听频道-log
* @return
*/
@Bean
public ContainerProperties containerPropertiesOfLog(){
ContainerProperties properties = new ContainerProperties(ConstantKafka.KAFKA_TOPIC1);
properties.setMessageListener(kafkaConsumerMessageListener());
return properties;
}
/**
* 监听频道-other
* @return
*/
@Bean
public ContainerProperties containerPropertiesOfOther(){
ContainerProperties properties = new ContainerProperties(ConstantKafka.KAFKA_TOPIC2);
properties.setMessageListener(kafkaConsumerMessageListener());
return properties;
}
@Bean(initMethod = "doStart")
public KafkaMessageListenerContainer kafkaMessageListenerContainerOfLog(){
KafkaMessageListenerContainer container = new KafkaMessageListenerContainer(defaultKafkaConsumerFactory(),containerPropertiesOfLog());
return container;
}
@Bean(initMethod = "doStart")
public KafkaMessageListenerContainer kafkaMessageListenerContainerOfOther(){
KafkaMessageListenerContainer container = new KafkaMessageListenerContainer(defaultKafkaConsumerFactory(),containerPropertiesOfOther());
return container;
}
3.生产消息服务
@Service
public class KafkaProducerServer implements IKafkaProducerServer {
@Autowired
private KafkaTemplate kafkaTemplate;
public static final String ROLE_LOG = "log";
public static final String ROLE_web = "web";
public static final String ROLE_APP = "app";
/**
* 发送消息
* @param topic 频道
* @param msg 消息对象
* @param isUsePartition 是否使用分区
* @param partitionNum 分区数,如果isUsePartition为true,此数值必须>0
* @param role 角色:app,web
* @return
* @throws IllegalServiceException
*/
@Override
public ResultResp<Void> send(String topic, Object msg, boolean isUsePartition, Integer partitionNum, String role) throws IllegalServiceException {
if (role == null){
role = ROLE_LOG;
}
String key = role + "_" + msg.hashCode();
String valueString = JsonUtil.ObjectToJson(msg, true);
if (isUsePartition) {
//表示使用分区
int partitionIndex = getPartitionIndex(key, partitionNum);
ListenableFuture<SendResult<String, Object>> result = kafkaTemplate.send(topic, partitionIndex, key, valueString);
return checkProRecord(result);
} else {
ListenableFuture<SendResult<String, Object>> result = kafkaTemplate.send(topic, key, valueString);
return checkProRecord(result);
}
}
/**
* 根据key值获取分区索引
*
* @param key
* @param num
* @return
*/
private int getPartitionIndex(String key, int num) {
if (key == null) {
Random random = new Random();
return random.nextInt(num);
} else {
int result = Math.abs(key.hashCode()) % num;
return result;
}
}
/**
* 检查发送返回结果record
*
* @param res
* @return
*/
private ResultResp<Void> checkProRecord(ListenableFuture<SendResult<String, Object>> res) {
ResultResp<Void> resp = new ResultResp<>();
resp.setCode(ConstantKafka.KAFKA_NO_RESULT_CODE);
resp.setInfo(ConstantKafka.KAFKA_NO_RESULT_MES);
if (res != null) {
try {
SendResult r = res.get();//检查result结果集
/*检查recordMetadata的offset数据,不检查producerRecord*/
Long offsetIndex = r.getRecordMetadata().offset();
if (offsetIndex != null && offsetIndex >= 0) {
resp.setCode(ConstantKafka.SUCCESS_CODE);
resp.setInfo(ConstantKafka.SUCCESS_MSG);
} else {
resp.setCode(ConstantKafka.KAFKA_NO_OFFSET_CODE);
resp.setInfo(ConstantKafka.KAFKA_NO_OFFSET_MES);
}
} catch (InterruptedException e) {
e.printStackTrace();
resp.setCode(ConstantKafka.KAFKA_SEND_ERROR_CODE);
resp.setInfo(ConstantKafka.KAFKA_SEND_ERROR_MES + ":" + e.getMessage());
} catch (ExecutionException e) {
e.printStackTrace();
resp.setCode(ConstantKafka.KAFKA_SEND_ERROR_CODE);
resp.setInfo(ConstantKafka.KAFKA_SEND_ERROR_MES + ":" + e.getMessage());
}
}
return resp;
}
}
4.生产者监听服务
public class KafkaProducerListener implements ProducerListener {
protected final Logger logger = Logger.getLogger(KafkaProducerListener.class.getName());
public KafkaProducerListener(){
}
@Override
public void onSuccess(String topic, Integer partition, Object key, Object value, RecordMetadata recordMetadata) {
logger.info("-----------------kafka发送数据成功");
logger.info("----------topic:"+topic);
logger.info("----------partition:"+partition);
logger.info("----------key:"+key);
logger.info("----------value:"+value);
logger.info("----------RecordMetadata:"+recordMetadata);
logger.info("-----------------kafka发送数据结束");
}
@Override
public void onError(String topic, Integer partition, Object key, Object value, Exception e) {
logger.info("-----------------kafka发送数据失败");
logger.info("----------topic:"+topic);
logger.info("----------partition:"+partition);
logger.info("----------key:"+key);
logger.info("----------value:"+value);
logger.info("-----------------kafka发送数据失败结束");
e.printStackTrace();
}
/**
* 是否启动Producer监听器
* @return
*/
@Override
public boolean isInterestedInSuccess() {
return false;
}
}
5.消费者监听服务
public class KafkaConsumerMessageListener implements MessageListener<String,Object> {
private Logger logger = Logger.getLogger(KafkaConsumerMessageListener.class.getName());
public KafkaConsumerMessageListener(){
}
/**
* 消息接收-LOG日志处理
* @param record
*/
@Override
public void onMessage(ConsumerRecord<String, Object> record) {
logger.info("=============kafka消息订阅=============");
String topic = record.topic();
String key = record.key();
Object value = record.value();
long offset = record.offset();
int partition = record.partition();
if (ConstantKafka.KAFKA_TOPIC1.equals(topic)){
doSaveLogs(value.toString());
}
logger.info("-------------topic:"+topic);
logger.info("-------------value:"+value);
logger.info("-------------key:"+key);
logger.info("-------------offset:"+offset);
logger.info("-------------partition:"+partition);
logger.info("=============kafka消息订阅=============");
}
private void doSaveLogs(String data){
SocketIOPojo<BikeLogPojo> logs = JsonUtil.JsonToObject(data.toString(),SocketIOPojo.class);
/**
* 写入到数据库中
*/
}
}
测试图片:


近期评论