推荐一款MongoDB的客户端工具–nosqlbooster,也是工作中一直使用的连接管理MongoDB的工具。这个工具还有个曾用名–mongobooster。nosqlbooster立志做“The Smartest IDE for MongoDB”。它支持 MongoDB v2.6-4.0所有版本,并且更新升级及时。它既有免费版,也有加强升级的付费版。
官网: https://nosqlbooster.com/downloads
工具支持Windows、Linux 和 Mac OS。
下面我将常见的一些操作 和大家讲解一下:
1.连接登入
step 1 点击上面工具栏的【Connect】按钮

step 2 在弹出的Connections 界面中 点击[Create]按钮。因为是第一次,连接信息要新建。

step 3 在弹出的Connection Editor 界面编辑登入信息。
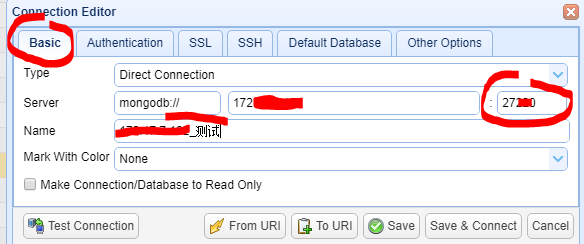
有三类信息要求输入:1. Basic;2.Authentication;3.Default Database。
1. Basic 编辑界面;
这时候大家一定要注意Port端口,因为它默认的是27017,大家要根据实际需求调整修改。还有就是Name是显示名称,可以修改为更有代表性的名称。
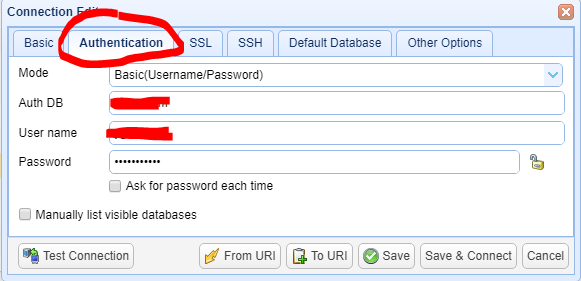
2.点击【Authentication】,此处需输入 Auth DB 数据(数据库名称),用户数据 和 密码数据
3.点击【Default DataBase】,进入Default DataBase界面。
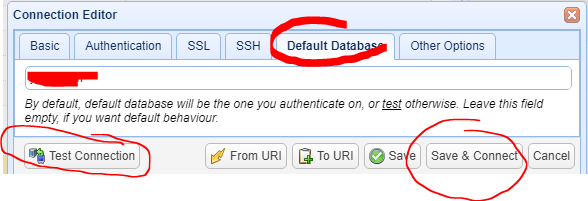
请一定要输入指定的数据库,否则可能提示错误,如:MongoError:Authentication Failed。或者可以登入进去,但是看不到任何 集合。

但是,随着版本的升级,新版本这个栏位的值在登入时可能会自动获取前面输入Auth DB的 输入值,但是目前来看还不是很稳定。
建议大家手动输入Default DataBase 数据。
2.打开一个新的查询界面
在很多工具,都会有一个打开查询界面的按钮。
例如:连接Sql Server的 SSMS客户端,工具栏很明显就有一个功能按钮【新建查询】

单纯的nosqlbooster工具没有这个选项,但是可以通过快捷方式来打开,如下:
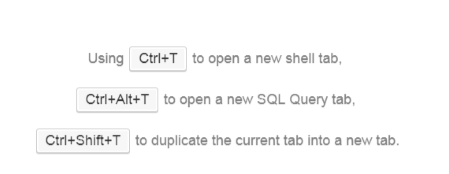
注意点击时,请先用鼠标点击选中要指定的集合或数据库
3.查询代码生成器
这个工具还有一个查询代码生成器,可以将用户编写的查询语言装换成 MongoDB Shell、JavaScript 、Java、C# 、Python 等各种语言。例如:
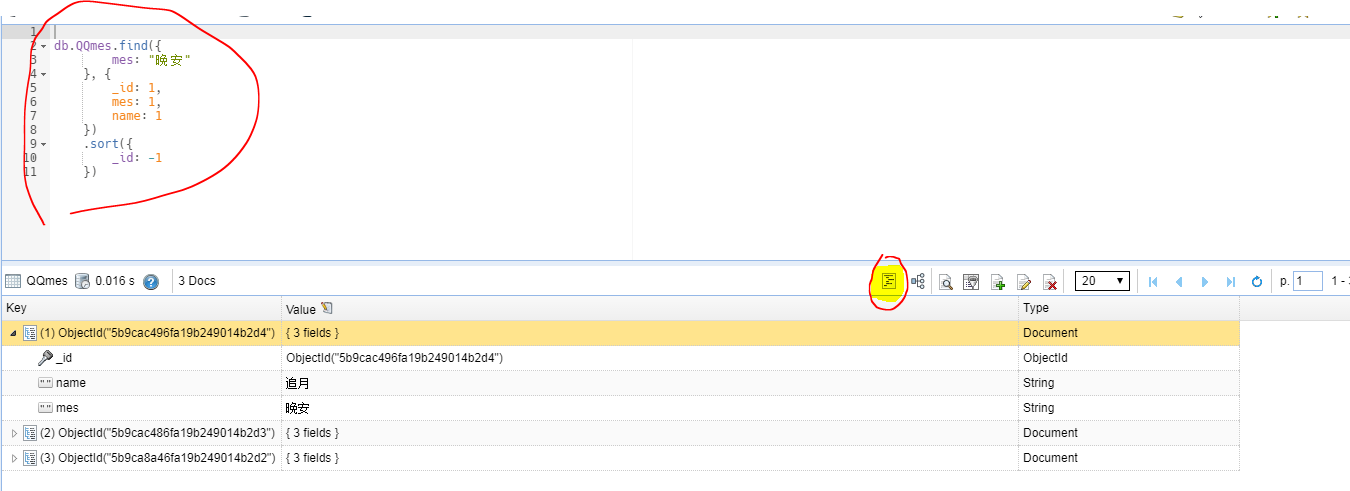
转换为C# 语句,我们可以看到很多C# 语言关于MongoDB的操作写法。
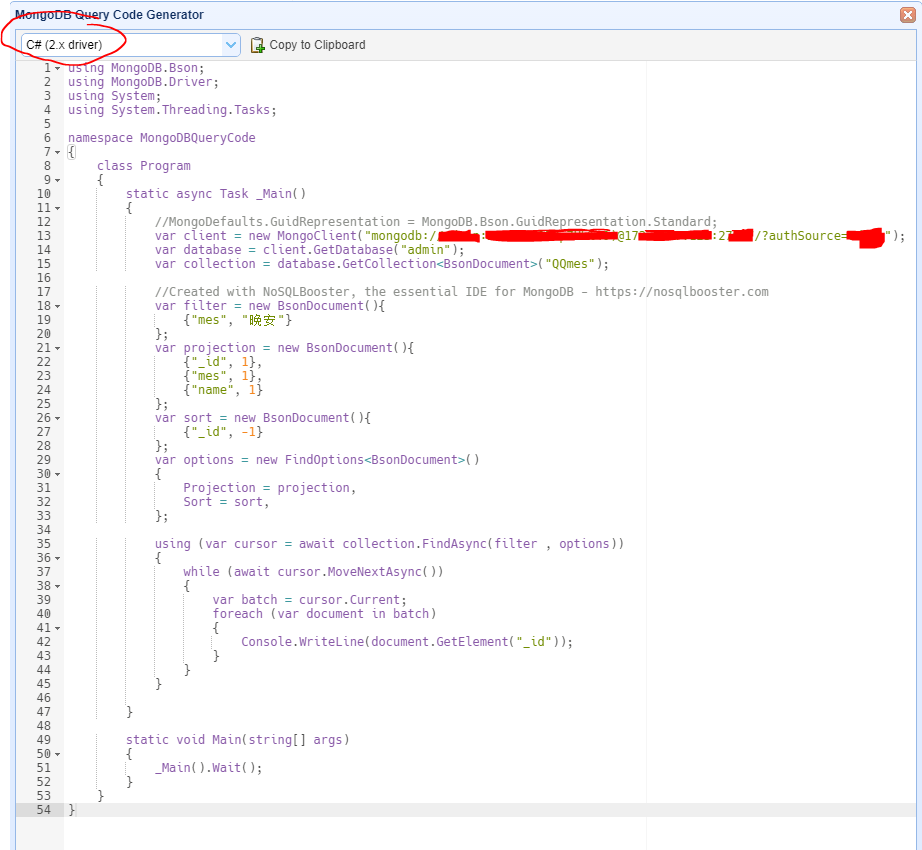
4. 查询语句生成器
刚学习MongoDB,对一些查询写法比较陌生,这个工具可以自动生成一些查询语句。生成器按钮,点击红色标注的[Query]
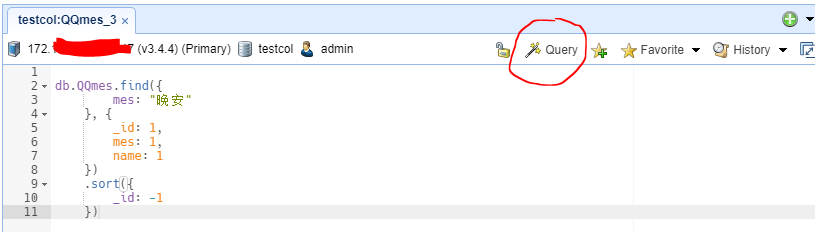
弹出可视化的查询编辑器,如下:
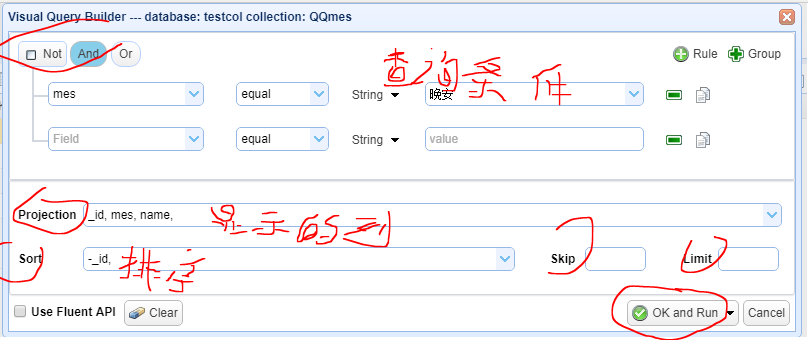
点击【OK and Run】就可以生成MongoDB Shell 查询语句。
一定要在生成了db.collectionname..find({}) 命令的界面上编辑,否则,点击Query无效
5.可以使用sql(结构化查询语言)查询
前面第2步中说过,点击【Ctrl+Alt+T】可以打开一个 sql 查询界面。例如
db.employees.aggregate([ { $group: { _id: “$department”,total: { $sum: “$salary” } },} ])
可以转换为sql语言,如下:
mb.runsqlQuery(` SELECT department,SUM(salary) AS total FROM employees GROUP BY department `);
其执行结果是一样的。
另外,为了促使自己尽快熟悉mongo语言,推荐大家还是使用mongo这种JSON类的语言,而不是sql的语言。
6.将查询出的数据导出到Excel文件中
在MongoDB的导出功能中支持JSON和CSV格式,而大家熟悉的Excel一般的工具很难支持,而我们可以通过nosqlbooster工具将少量数据导出到Excel中(所谓的少量数据要求主要受限于本地内存)。
下面以导出集合testexportToexcel的数据为例,进行演示说明。
step 1 执行查询语句
step 2 将显示格式调整为 Table 格式

step 3 按Shift 键,选中所要导出的数据

step 4 在选中的数据区域中,鼠标右击,选中【copy Document(s) to Clipboard -Tab-Separted Values】
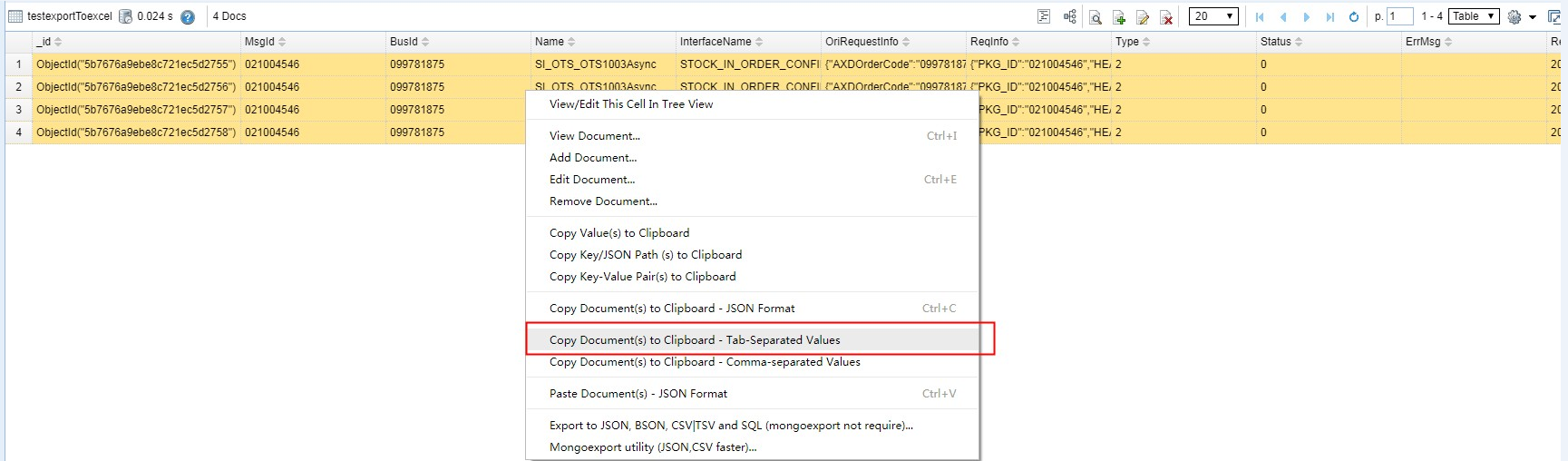
step 5 粘贴至excel文件中,即可。

近期评论