使用C/C++新建了一个类似于Java的StringBuffer类,主要实现了常规的几种方法:
1.StringBuffer & append(const char * _c) ;
这个方法是往字符串中插入字符到最后;
2.StringBuffer(const StringBuffer & buf);
在C语言中如果需要使用到a=b这种赋值方法,并且数据成员使用指针形式,那么则需要自定义一个复制函数;
3.char* toString();
返回数据成员中的char数据;
4.int length();
返回字符串的长度;
5.std::string substr(int start = 0,int len = 1);
截取字符串,通常需要借助indexOf的方法来查找字符串的位置;
6.void replaceAll(const char * find, const char * des);
替换字符串中的指定文字;
7.int indexOf(const char * find);
查找指定字符串的位置,如果没有则返回-1;
8.bool operator==(const StringBuffer & buf);
C/C++中特有的方法,如果需要使用运算符:a==b,增需要定义一个自定义的运算符方法,这里只定义了:==。
接着就是贴出头文件:StringBuffer.h
#pragma once
#include<iostream>
//exmple:
/*
// StringBuffer sb;
// or like this:
// StringBuffer sb("test");
// sb.append("append.");
// and you can like this:
// sb.append("append 1,").append("append 2,");
// equal:
// sb1==sb?1:0
// if(sb1 == sb){//do something...}
// length:
// sb.length();
// substring:
// sb.substr(int strat,int end);
// sb.substr(0,1);//it will be return "t";
// find:
// sb.indexOf(char * find_char);
// sb.indexOf("st");//it will be return 2;
// sb.indexOf("index");//it will be return -1;
// replaceAll:
// sb.replaceAll(char * find_char,char * des_char);
// like this:
// sb.replaceAll("test","1234");
// toString:
// sb.toString();
*/
#ifndef STRING_BUFFER
#define STRING_BUFFER
class StringBuffer
{
private:
char * value;
char * value1;
int len;
int _number;
public:
StringBuffer();
StringBuffer(const char * _c);
StringBuffer & append(const char * _c) ;
StringBuffer(const StringBuffer & buf);
char* toString();
int length();
std::string substr(int start = 0,int len = 1);
void replaceAll(const char * find, const char * des);
int indexOf(const char * find);
bool operator==(const StringBuffer & buf);
~StringBuffer();
};
#endif // !STRING_BUFFER
然后贴出代码:
#include "pch.h"
#include "StringBuffer.h"
#include<iostream>
#include<string.h>
StringBuffer::StringBuffer()
{
len = 1;
_number = 0;
value = new char[2]{"\0"};
}
StringBuffer::StringBuffer(const char * _c) {
len = std::strlen(_c) + 1;
_number = 1;
value = new char[len];
strcpy_s(value, len, _c);
}
StringBuffer::StringBuffer(const StringBuffer & buf) {
len = buf.len;
_number = buf._number;
value = new char[len];
strcpy_s(value, len, buf.value);
}
StringBuffer::~StringBuffer()
{
delete[] value;
std::cout << "StringBuffer out." << std::endl;
}
StringBuffer & StringBuffer::append(const char * _c) {
int _l = std::strlen(_c)+1;
value1 = new char[len+_l];
strcpy_s(value1, len, value);
strcat_s(value1, len + _l, _c);
value = value1;
len += _l;
_number++;
return *this;
}
char* StringBuffer::toString() {
return this->value;
}
int StringBuffer::length() {
return strlen(value);
}
std::string StringBuffer::substr(int start, int len) {
std::string s = value;
return s.substr(start, len);
}
int StringBuffer::indexOf(const char * find) {
std::string s = value;
return s.find(find);
}
void StringBuffer::replaceAll(const char * find, const char * des) {
int idx = 0;
int _len = std::strlen(find);
bool has = false;
std::string s = value;
while (idx > -1)
{
idx = s.find(find);
if (idx > -1) {
s = s.replace(idx, _len, des);
has = true;
}
}
if (has) {
strcpy_s(value, strlen(s.data()) + 1, s.data());
len = strlen(s.data()) + 1;
value1 = value;
}
}
bool StringBuffer::operator==(const StringBuffer & buf) {
if (this == &buf) {
return true;
}
return strcmp(this->value, buf.value) == 0;
}
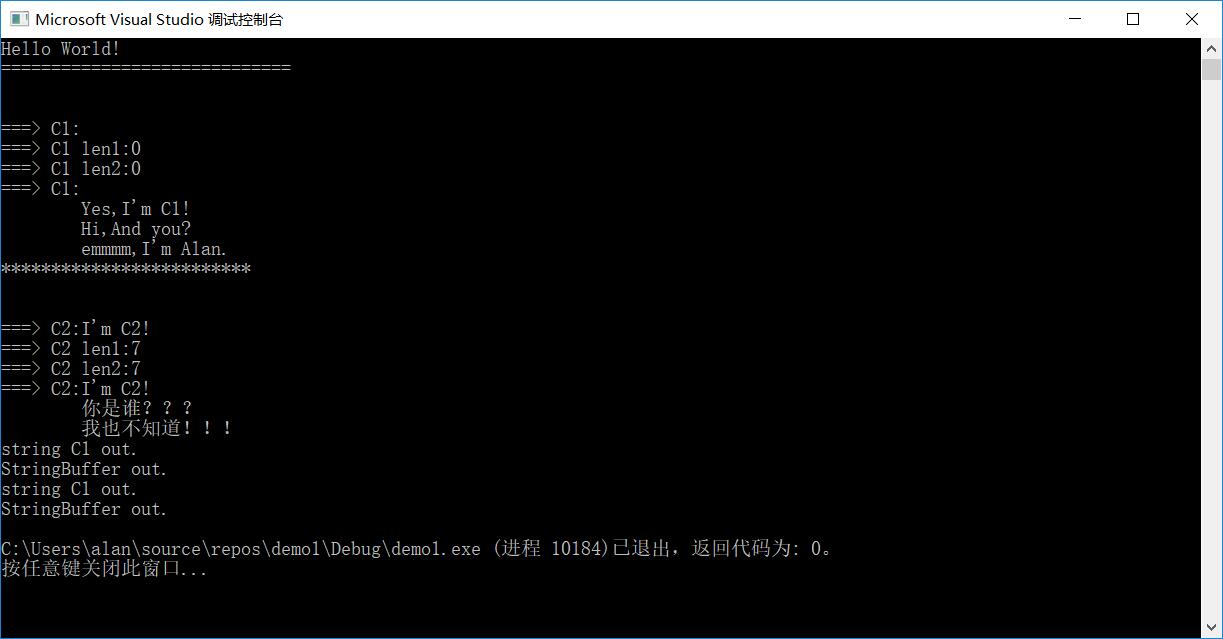
来一张效果图呗:

近期评论