一、哨兵模式概述
哨兵模式是一种特殊的模式,首先Redis提供了哨兵的命令,哨兵是一个独立的进程,作为进程,它会独立运行。其原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例。
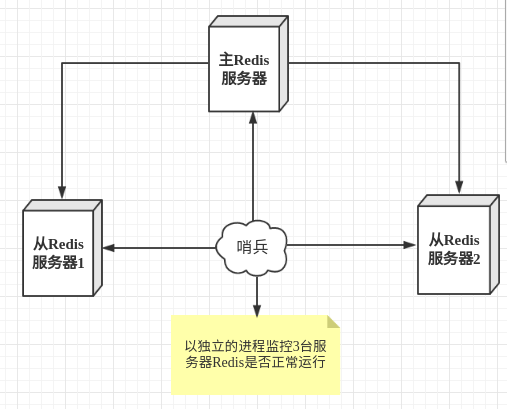
这里的哨兵有两个作用
- 通过发送命令,让Redis服务器返回监控其运行状态,包括主服务器和从服务器。
- 当哨兵监测到master宕机,会自动将slave切换成master,然后通过发布订阅模式通知其他的从服务器,修改配置文件,让它们切换主机。
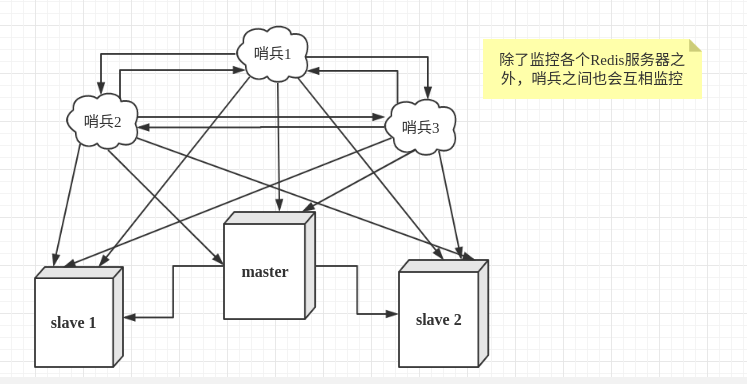
然而一个哨兵进程对Redis服务器进行监控,可能会出现问题,为此,我们可以使用多个哨兵进行监控。各个哨兵之间还会进行监控,这样就形成了多哨兵模式。
用文字描述一下故障切换(failover)的过程。假设主服务器宕机,哨兵1先检测到这个结果,系统并不会马上进行failover过程,仅仅是哨兵1主观的认为主服务器不可用,这个现象成为主观下线。当后面的哨兵也检测到主服务器不可用,并且数量达到一定值时,那么哨兵之间就会进行一次投票,投票的结果由一个哨兵发起,进行failover操作。切换成功后,就会通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主机,这个过程称为客观下线。这样对于客户端而言,一切都是透明的。
二、Redis配置哨兵模式
配置3个哨兵和1主2从的Redis服务器来演示这个过程。
| 服务类型 | 是否是主服务器 | IP地址 | 端口 |
|---|---|---|---|
| Redis | 是 | 192.168.11.128 | 6379 |
| Redis | 否 | 192.168.11.129 | 6379 |
| Redis | 否 | 192.168.11.130 | 6379 |
| Sentinel | – | 192.168.11.128 | 26379 |
| Sentinel | – | 192.168.11.129 | 26379 |
| Sentinel | – | 192.168.11.130 | 26379 |
首先配置Redis的主从服务器,修改redis.conf文件如下
# 使得Redis服务器可以跨网络访问
bind 0.0.0.0
# 设置密码
requirepass "123456"
# 指定主服务器,注意:有关slaveof的配置只是配置从服务器,主服务器不需要配置
slaveof 192.168.11.128 6379
# 主服务器密码,注意:有关slaveof的配置只是配置从服务器,主服务器不需要配置
masterauth 123456
上述内容主要是配置Redis服务器,从服务器比主服务器多一个slaveof的配置和密码。
配置3个哨兵,每个哨兵的配置都是一样的。在Redis安装目录下有一个sentinel.conf文件,copy一份进行修改
# 禁止保护模式
protected-mode no
# 配置监听的主服务器,这里sentinel monitor代表监控,mymaster代表服务器的名称,可以自定义,192.168.11.128代表监控的主服务器,6379代表端口,2代表只有两个或两个以上的哨兵认为主服务器不可用的时候,才会进行failover操作。
sentinel monitor mymaster 192.168.11.128 6379 2
# sentinel author-pass定义服务的密码,mymaster是服务名称,123456是Redis服务器密码
# sentinel auth-pass <master-name> <password>
sentinel auth-pass mymaster 123456
上述关闭了保护模式,便于测试。
有了上述的修改,我们可以进入Redis的安装目录的src目录,通过下面的命令启动服务器和哨兵
# 启动Redis服务器进程
./redis-server ../redis.conf
# 启动哨兵进程
./redis-sentinel ../sentinel.conf
注意启动的顺序。首先是主机(192.168.11.128)的Redis服务进程,然后启动从机的服务进程,最后启动3个哨兵的服务进程。
三、Java中使用哨兵模式
/**
* 测试Redis哨兵模式
* @author liu
*/
public class TestSentinels {
@SuppressWarnings("resource")
@Test
public void testSentinel() {
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
jedisPoolConfig.setMaxTotal(10);
jedisPoolConfig.setMaxIdle(5);
jedisPoolConfig.setMinIdle(5);
// 哨兵信息
Set<String> sentinels = new HashSet<>(Arrays.asList("192.168.11.128:26379",
"192.168.11.129:26379","192.168.11.130:26379"));
// 创建连接池
JedisSentinelPool pool = new JedisSentinelPool("mymaster", sentinels,jedisPoolConfig,"123456");
// 获取客户端
Jedis jedis = pool.getResource();
// 执行两个命令
jedis.set("mykey", "myvalue");
String value = jedis.get("mykey");
System.out.println(value);
}
}
上面是通过Jedis进行使用的,同样也可以使用Spring进行配置RedisTemplate使用。
<bean id = "poolConfig" class="redis.clients.jedis.JedisPoolConfig">
<!-- 最大空闲数 -->
<property name="maxIdle" value="50"></property>
<!-- 最大连接数 -->
<property name="maxTotal" value="100"></property>
<!-- 最大等待时间 -->
<property name="maxWaitMillis" value="20000"></property>
</bean>
<bean id="connectionFactory" class="org.springframework.data.redis.connection.jedis.JedisConnectionFactory">
<constructor-arg name="poolConfig" ref="poolConfig"></constructor-arg>
<constructor-arg name="sentinelConfig" ref="sentinelConfig"></constructor-arg>
<property name="password" value="123456"></property>
</bean>
<!-- JDK序列化器 -->
<bean id="jdkSerializationRedisSerializer" class="org.springframework.data.redis.serializer.JdkSerializationRedisSerializer"></bean>
<!-- String序列化器 -->
<bean id="stringRedisSerializer" class="org.springframework.data.redis.serializer.StringRedisSerializer"></bean>
<bean id="redisTemplate" class="org.springframework.data.redis.core.RedisTemplate">
<property name="connectionFactory" ref="connectionFactory"></property>
<property name="keySerializer" ref="stringRedisSerializer"></property>
<property name="defaultSerializer" ref="stringRedisSerializer"></property>
<property name="valueSerializer" ref="jdkSerializationRedisSerializer"></property>
</bean>
<!-- 哨兵配置 -->
<bean id="sentinelConfig" class="org.springframework.data.redis.connection.RedisSentinelConfiguration">
<!-- 服务名称 -->
<property name="master">
<bean class="org.springframework.data.redis.connection.RedisNode">
<property name="name" value="mymaster"></property>
</bean>
</property>
<!-- 哨兵服务IP和端口 -->
<property name="sentinels">
<set>
<bean class="org.springframework.data.redis.connection.RedisNode">
<constructor-arg name="host" value="192.168.11.128"></constructor-arg>
<constructor-arg name="port" value="26379"></constructor-arg>
</bean>
<bean class="org.springframework.data.redis.connection.RedisNode">
<constructor-arg name="host" value="192.168.11.129"></constructor-arg>
<constructor-arg name="port" value="26379"></constructor-arg>
</bean>
<bean class="org.springframework.data.redis.connection.RedisNode">
<constructor-arg name="host" value="192.168.11.130"></constructor-arg>
<constructor-arg name="port" value="26379"></constructor-arg>
</bean>
</set>
</property>
</bean>
四、哨兵模式的其他配置项
| 配置项 | 参数类型 | 作用 |
|---|---|---|
| port | 整数 | 启动哨兵进程端口 |
| dir | 文件夹目录 | 哨兵进程服务临时文件夹,默认为/tmp,要保证有可写入的权限 |
| sentinel down-after-milliseconds | <服务名称><毫秒数(整数)> | 指定哨兵在监控Redis服务时,当Redis服务在一个默认毫秒数内都无法回答时,单个哨兵认为的主观下线时间,默认为30000(30秒) |
| sentinel parallel-syncs | <服务名称><服务器数(整数)> | 指定可以有多少个Redis服务同步新的主机,一般而言,这个数字越小同步时间越长,而越大,则对网络资源要求越高 |
| sentinel failover-timeout | <服务名称><毫秒数(整数)> | 指定故障切换允许的毫秒数,超过这个时间,就认为故障切换失败,默认为3分钟 |
| sentinel notification-script | <服务名称><脚本路径> | 指定sentinel检测到该监控的redis实例指向的实例异常时,调用的报警脚本。该配置项可选,比较常用 |
sentinel down-after-milliseconds配置项只是一个哨兵在超过规定时间依旧没有得到响应后,会自己认为主机不可用。对于其他哨兵而言,并不是这样认为。哨兵会记录这个消息,当拥有认为主观下线的哨兵达到sentinel monitor所配置的数量时,就会发起一次投票,进行failover,此时哨兵会重写Redis的哨兵配置文件,以适应新场景的需要。

近期评论