快排的算法其实不复杂,但是很少时候,偶尔整的自己头晕,所以写一篇博客,以免以后忘记。
假设我们的数组为:{5,2,1,8,9,3,7,0,4,6},一共10个数字,现在需要将这个数组进行排序。首先我们需要找一个基准数,其实就是参照物,得有个东西跟你对比吧?不然怎么可以呈现出你的美?
假设左边为i=0; 右边j = 9;
方法很简单,分别从数组的左右边两段进行“探测”。首先是左边移动,最左边的第一个数字是5,而最右边的数字是6。
6 >= 5 条件成立,接着左边往右边移动一位(j–)
……
4>=5条件不成立,这个时候就换一下位置,4跟5换。现在的数组应该就是这样子:{4,2,1,8,9,3,7,0,5,6}
接着轮到右边探测,左边的数字已经被替换为4,而右边的是5(因为j自减了一次);那么现在条件对比:
5>=4条件成立,右边往左边靠拢(i++)
5>=2条件成立,右边往左边靠拢(i++)
……
5>=8条件不成立,换位置:{4,2,1,5,9,3,7,0,8,6}
到此,第一轮交换结束。接下来j继续向左挪动(再友情提醒,每次必须是j先出发)。他发现了0(比基准数5要小,满足要求)之后停了下来。此时再次进行交换,交换之后的序列如下:
{4,2,1,0,9,3,7,5,8,6}
第二次交换结束,“探测”继续。接着轮到i继续向右挪动,他发现了9(比基准数5要大,满足要求)之后又停了下来。交换之后的序列如下:
{4,2,1,0,5,3,7,9,8,6}
….以此类推,哨兵i继续向右移动,悲剧!!!此时i和j撞上了,说明此时“探测”结束。我们将基准数5和3进行交换。交换之后的序列如下:
{4,2,1,0,3,5,7,9,8,6}
到此“探测”真正结束。此时以基准数5为分界点,5左边的数都小于等于5,5右边的数都大于等于5。
回顾一下刚才的过程,其实j的使命就是要找小于基准数(5)的数,而哨兵i的使命就是要找大于基准数(5)的数,直到i和j撞在一起为止为止。
那么现在数据可以区分为两组:
{4,2,1,0,3, 5 ,7,9,8,6}
左边:4 2 1 0 3
右边:7 9 8 6
数组被分为了两组,然后按照直接的方法进行对比,只是开始i=0;j=9,要变为(先从左边开始):
指针位置:i=0; j=4
数组:4 2 1 0 3
还是上一张图吧,比较好理解:
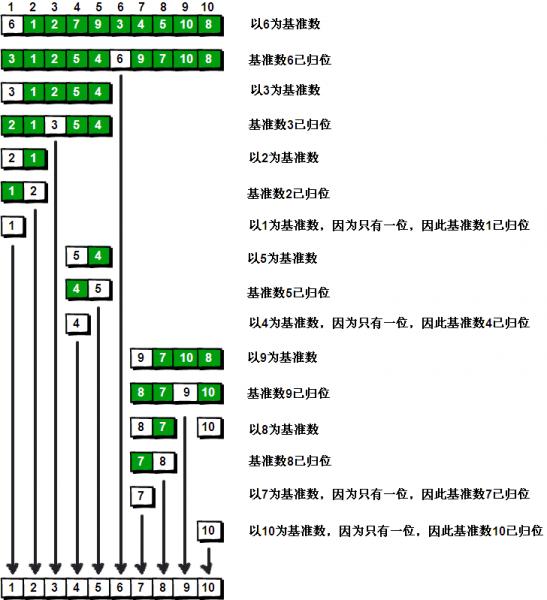
注:图片是网上找的,数组的排序跟我的不一致,但是看的明白。
最后:
- 快排的原理很简单;
- 就是把数组分为两节;
- 左边的是最小的,而右边的是最大的;
- 然后再拿左、右边的来继续递归,递归的原理也一样,也是拆分为两节,以此类推。
上代码吧,我写了java跟c的代码:
2.java代码:
public static void main(String[] args) {
int[] arr = {5,2,1,8,9,3,7,0,4,6};
sort(arr, 0, arr.length - 1);
for (int i : arr) {
System.out.print(i + " ");
}
}
private static void sort(int[] arr, int l, int r) {
int i = l;
int j = r;
if (l < r) {
while (l < r) {
while (l < r && arr[r] >= arr[l]) {
r--;
}
int tmp = arr[l];
arr[l] = arr[r];
arr[r] = tmp;
while (l < r && arr[l] <= arr[r]) {
l++;
}
tmp = arr[l];
arr[l] = arr[r];
arr[r] = tmp;
}
sort(arr, i, l - 1);//递归左边,此时l=5
sort(arr, l + 1, j);//递归右边,此时l=5
}
}
2.那么c++的代码会是怎么样呢?
#include "pch.h"
#include <iostream>
using namespace std;
void sortQ(int *arr, int l, int r) {
int i = l;
int j = r;
int tmp;
if (i < j) {
while (l < r) {
while (l < r && arr[r] >= arr[l])
{
r--;
}
tmp = arr[l];
arr[l] = arr[r];
arr[r] = tmp;
while (l < r && arr[r] >= arr[l]) {
l++;
}
tmp = arr[l];
arr[l] = arr[r];
arr[r] = tmp;
}
sortQ(arr, i, l - 1);//处理左边,此时l=5
sortQ(arr, l + 1, j);//处理右边,此时l=5
}
}
int main()
{
std::cout << "Hello World!\n";
int arr[] = {5,2,1,8,9,3,7,0,4,6};
int size = sizeof(arr) / sizeof(arr[0]);
sortQ(arr, 0, size - 1);
for (int i : arr) {
cout << i << " ";
}
}

近期评论